Download as PDF, PPTX









![Open Street Map Data
#!/usr/bin/env python
# Data Source
# http://www.overpass-api.de/api/xapi?*[amenity=pub][bbox=-10.5,49.78,1.78,59]
import re
import sys
from imposm.parser import OSMParser
import pymongo
class Handler(object):
def nodes(self, nodes):
if not nodes:
return
docs = []
for node in nodes:
osm_id, doc, (lon, lat) = node
if "name" not in doc:
node_points[osm_id] = (lon, lat)
continue
doc["name"] = doc["name"].title().lstrip("The ").replace("And", "&")
doc["_id"] = osm_id
doc["location"] = {"type": "Point", "coordinates": [lon, lat]}
docs.append(doc)
collection.insert(docs)](https://image.slidesharecdn.com/10-31dataprocessingandaggregation-131031155605-phpapp01/85/Webinar-Data-Processing-and-Aggregation-Options-11-320.jpg)
![Example Pub Data
{
"_id" : 451152,
"amenity" : "pub",
"name" : "The Dignity",
"addr:housenumber" : "363",
"addr:street" : "Regents Park Road",
"addr:city" : "London",
"addr:postcode" : "N3 1DH",
"toilets" : "yes",
"toilets:access" : "customers",
"location" : {
"type" : "Point",
"coordinates" : [-0.1945732, 51.6008172]
}
}](https://image.slidesharecdn.com/10-31dataprocessingandaggregation-131031155605-phpapp01/85/Webinar-Data-Processing-and-Aggregation-Options-12-320.jpg)
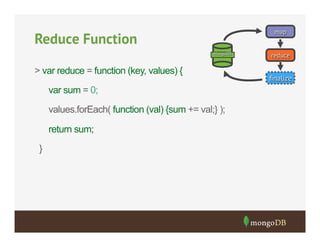

![Pub Names in the Center of London
> db.pubs.mapReduce(map, reduce, { out: "pub_names",
query: {
location: {
$within: { $centerSphere: [[-0.12, 51.516], 2 / 3959] }
}}
})
{
"result" : "pub_names",
"timeMillis" : 116,
"counts" : {
"input" : 643,
"emit" : 643,
"reduce" : 54,
"output" : 537
},
"ok" : 1,
}](https://image.slidesharecdn.com/10-31dataprocessingandaggregation-131031155605-phpapp01/85/Webinar-Data-Processing-and-Aggregation-Options-19-320.jpg)










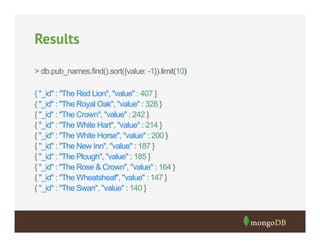
![Open Street Map Data
#!/usr/bin/env python
# Data Source
# http://www.overpass-api.de/api/xapi?*[amenity=pub][bbox=-10.5,49.78,1.78,59]
import re
import sys
from imposm.parser import OSMParser
import pymongo
class Handler(object):
def nodes(self, nodes):
if not nodes:
return
docs = []
for node in nodes:
osm_id, doc, (lon, lat) = node
if "name" not in doc:
node_points[osm_id] = (lon, lat)
continue
doc["name"] = doc["name"].title().lstrip("The ").replace("And", "&")
doc["_id"] = osm_id
doc["location"] = {"type": "Point", "coordinates": [lon, lat]}
docs.append(doc)
collection.insert(docs)](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-11-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)
![Example Pub Data
{
"_id" : 451152,
"amenity" : "pub",
"name" : "The Dignity",
"addr:housenumber" : "363",
"addr:street" : "Regents Park Road",
"addr:city" : "London",
"addr:postcode" : "N3 1DH",
"toilets" : "yes",
"toilets:access" : "customers",
"location" : {
"type" : "Point",
"coordinates" : [-0.1945732, 51.6008172]
}
}](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-12-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)






![Pub Names in the Center of London
> db.pubs.mapReduce(map, reduce, { out: "pub_names",
query: {
location: {
$within: { $centerSphere: [[-0.12, 51.516], 2 / 3959] }
}}
})
{
"result" : "pub_names",
"timeMillis" : 116,
"counts" : {
"input" : 643,
"emit" : 643,
"reduce" : 54,
"output" : 537
},
"ok" : 1,
}](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-19-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)











![Matching Field Values
{
"_id" : 271421,
"amenity" : "pub",
"name" : "Sir Walter Tyrrell",
"location" : {
"type" : "Point",
"coordinates" : [
-1.6192422,
50.9131996
]
}
}
{ "$match": {
"name": "The Red Lion"
}}
{
"_id" : 271466,
"amenity" : "pub",
"name" : "The Red Lion",
"location" : {
"type" : "Point",
"coordinates" : [
-1.5494749,
50.7837119
]}
{
"_id" : 271466,
"amenity" : "pub",
"name" : "The Red Lion",
"location" : {
"type" : "Point",
"coordinates" : [
-1.5494749,
50.7837119
]
}
}](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-31-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)

![Including and Excluding Fields
{
"_id" : 271466,
"amenity" : "pub",
"name" : "The Red Lion",
"location" : {
"type" : "Point",
{ “$project”: {
“_id”: 0,
“amenity”: 1,
“name”: 1,
}}
"coordinates" : [
-1.5494749,
50.7837119
]
}
}
{
“amenity” : “pub”,
“name” : “The Red Lion”
}](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-33-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)
![Reformatting Documents
{
"_id" : 271466,
"amenity" : "pub",
"name" : "The Red Lion",
"location" : {
"type" : "Point",
{ “$project”: {
“_id”: 0,
“name”: 1,
“meta”: {
“type”: “$amenity”}
}}
"coordinates" : [
-1.5494749,
50.7837119
]
}
}
{
“name” : “The Red Lion”
“meta” : {
“type” : “pub”
}}](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-34-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)


![Add To Set
{
title: "The Great Gatsby",
pages: 218,
language: "English"
{ $group: {
_id: "$language",
titles: { $addToSet: "$title" }
}}
}
{
{
title: "War and Peace",
pages: 1440,
language: "Russian"
}
{
}
{
title: "Atlas Shrugged",
pages: 1088,
language: "English"
}
}
_id: "Russian",
titles: [ "War and Peace" ]
_id: "English",
titles: [
"Atlas Shrugged",
"The Great Gatsby"
]](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-37-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)
![Expanding Arrays
{ $unwind: "$subjects" }
{
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: [
"Long Island",
"New York",
"1920s"
]
{
}
{
}
}
{
}
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: "Long Island"
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: "New York"
title: "The Great Gatsby",
ISBN: "9781857150193",
subjects: "1920s"](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-38-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)

![Popular Pub Names
>var popular_pub_names = [
{ $match : location:
{ $within: { $centerSphere:
[[-0.12, 51.516], 2 / 3959]}}}
},
{ $group :
{ _id: “$name”
value: {$sum: 1} }
},
{ $sort : {value: -1} },
{ $limit : 10 }](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-40-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)
![Results
> db.pubs.aggregate(popular_pub_names)
{
"result" : [
{ "_id" : "All Bar One", "value" : 11 }
{ "_id" : "The Slug & Lettuce", "value" : 7 }
{ "_id" : "The Coach & Horses", "value" : 6 }
{ "_id" : "The Green Man", "value" : 5 }
{ "_id" : "The Kings Arms", "value" : 5 }
{ "_id" : "The Red Lion", "value" : 5 }
{ "_id" : "Corney & Barrow", "value" : 4 }
{ "_id" : "O'Neills", "value" : 4 }
{ "_id" : "Pitcher & Piano", "value" : 4 }
{ "_id" : "The Crown", "value" : 4 }
],
"ok" : 1
}](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-41-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)




![Map Pub Names in Python
#!/usr/bin/env python
from pymongo_hadoop import BSONMapper
def mapper(documents):
bounds = get_bounds() # ~2 mile polygon
for doc in documents:
geo = get_geo(doc["location"]) # Convert the geo type
if not geo:
continue
if bounds.intersects(geo):
yield {'_id': doc['name'], 'count': 1}
BSONMapper(mapper)
print >> sys.stderr, "Done Mapping."](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-46-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)
![Reduce Pub Names in Python
#!/usr/bin/env python
from pymongo_hadoop import BSONReducer
def reducer(key, values):
_count = 0
for v in values:
_count += v['count']
return {'_id': key, 'value': _count}
BSONReducer(reducer)](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2F10-31dataprocessingandaggregation-131031155605-phpapp01%2F85%2FWebinar-Data-Processing-and-Aggregation-Options-47-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fwebinar-data-processing-and-aggregation-options%2F27790739&__type=image)















The document discusses data processing and aggregation using MongoDB, highlighting its capabilities in managing big data with high performance and a robust query interface. It demonstrates methods such as MapReduce and the aggregation framework for analyzing and processing data, including examples related to popular pub names in London. Additionally, it mentions integration with Hadoop for external data processing and compares the advantages and limitations of various data processing options.
































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































