






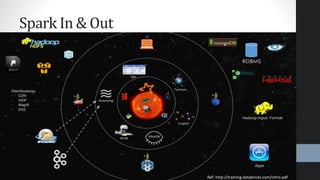
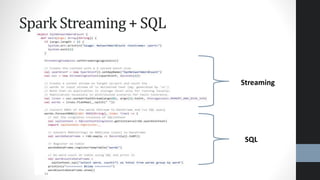

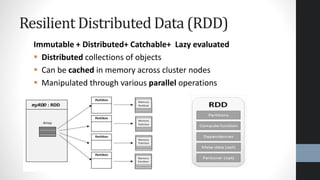
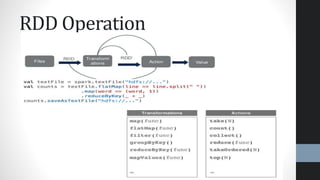

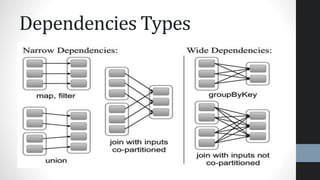
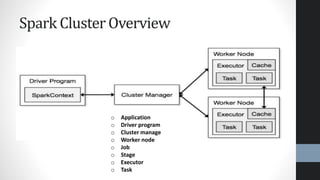
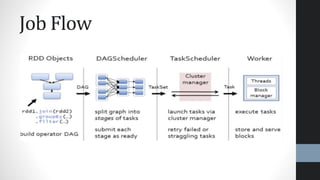








































































This document provides an overview of Apache Spark, highlighting its advantages over traditional big data processing frameworks like Hadoop, including faster processing speeds and improved fault tolerance. It discusses Spark's architecture, key components such as resilient distributed datasets (RDDs) and Spark SQL, as well as integrations with various data sources and libraries for machine learning and graph processing. The document also touches on data science processes and optimizations for effective big data analytics.













































































