Download as PDF, PPTX











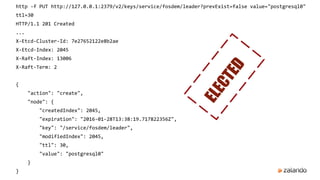





















![http -f PUT http://127.0.0.1:2379/v2/keys/service/fosdem/leader?prevValue="bar" value="bar"
HTTP/1.1 412 Precondition Failed
Content-Length: 89
Content-Type: application/json
Date: Thu, 28 Jan 2016 13:45:27 GMT
X-Etcd-Cluster-Id: 7e27652122e8b2ae
X-Etcd-Index: 2090
{
"cause": "[bar != postgresql0]",
"errorCode": 101,
"index": 2090,
"message": "Compare failed"
}
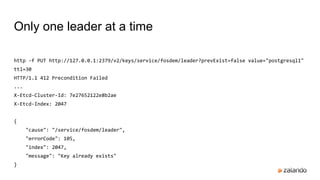
Only the leader can update the lock](/p?url=https%3A%2F%2Fimage.slidesharecdn.com%2Fhapostgresqlwithpatroni-160203093005%2F85%2FHigh-Availability-PostgreSQL-with-Zalando-Patroni-22-320.jpg&__src=https%3A%2F%2Fwww.slideshare.net%2Fslideshow%2Fhigh-availability-postgresql-with-zalando-patroni%2F57820504&__type=image)


























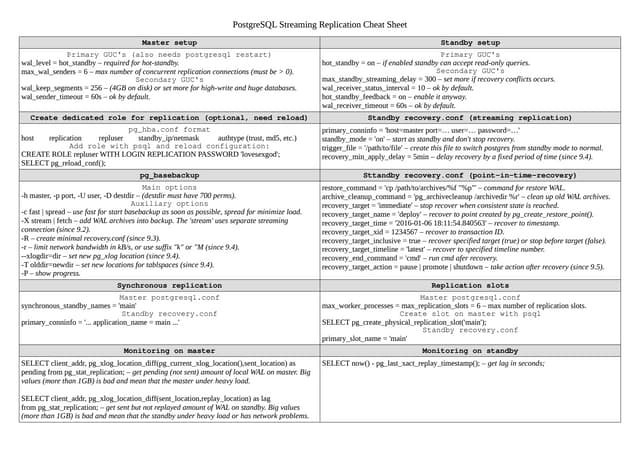
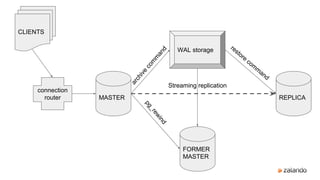
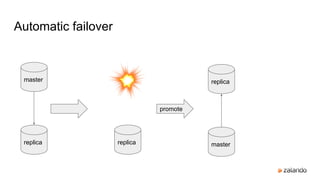
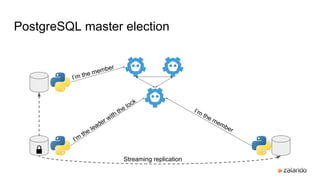
The document discusses the high availability of PostgreSQL using Patroni, including master election, streaming replication, and failover management. It explains components like etcd for leader election and consensus, configuration parameters for Patroni, and the use of pg_rewind for recovering from master failures. Additionally, it outlines the implementation details and provides guidance on setting up the system, including HAProxy configuration and user-defined scripts.