






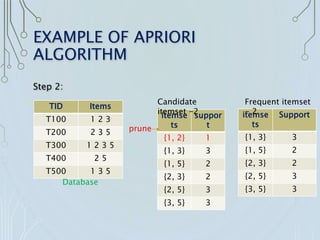
















The apriori algorithm is a crucial method for mining frequent itemsets for boolean association rules by iteratively generating candidate itemsets and determining which are frequent based on support count. It highlights that every subset of a frequent itemset must also be frequent and describes the process of candidate generation, pruning, and association rule creation. Despite its advantages, such as the ability to handle large itemsets and ease of implementation, the algorithm has drawbacks like high memory usage and multiple database scans.























































































