diff --git a/README.md b/README.md
index 6e75f41..860f932 100644
--- a/README.md
+++ b/README.md
@@ -1,9 +1,5 @@
# 🔥 微信公众号 : 码上Java
-
-
-> 关注微信订阅号: 码上Java 回复关键字 : 1 领取后端面试大礼包(简历模板、面试题、Java、数据结构、算法、数据库、python、操作系统、网络等)
-
[](https://jq.qq.com/?_wv=1027&k=5HPYvQk)

[](https://msjavacoder.github.io/msJava)
@@ -11,110 +7,10 @@


-| ♨ | ⭕ | 🔐 | 💈 | 💻 | 🚏 | 🔭 | 🏖 | 📰 | 📮 | 🔍 | 🗽 | 🚀 | 🌈 | ☎ |
-| :-----------------------------: | :-------------: | :----------------------------: | :---------: | :-----------: | :---------------------: | --------------- | --------------- | :---------------------------------: | :-----------------: | :-----------------------: | :---------------: | ----------------- | :-----------------: | :---------------------: |
-| [Java核心基础](#♨-java核心基础) | [集合](#⭕-集合) | [多线程](#%f0%9f%94%90-多线程) | [IO](#💈-io) | [JVM](#💻-jvm) | [设计模式](#🚏-设计模式) | [网络](#🔭-网络) | [框架](#🏖-框架) | [数据结构与算法](#📰-数据结构与算法) | [数据库](#📰-数据库) | [算法](#📰-数据结构与算法) | [Redis](#🗽-redis) | [Linux](#🚀-linux) | [面试题](#🌈-面试题) | [联系作者](#☎-联系作者) |
-
----
-
-### ♨ Java核心基础
-
-- [理解基本数据类型与包装类](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解基本数据类型与包装类.md)
-- [理解类与Object](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解类与Object.md)
-- [理解泛型与迭代器](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解泛型与迭代器.md)
-- [理解Java关键字](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/Java关键字理解.md)
-- [理解String字符串](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解String字符串.md)
-- [浅克隆和深克隆](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/浅克隆和深克隆.md)
-- [理解动态代理](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解动态代理.md)
-- [理解抽象类与接口](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解抽象类与接口.md)
-- [理解异常处理](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解异常处理.md)
-- [理解数据结构队列](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解数据结构队列.md)
-- [理解内部类与枚举类](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/各种内部类和枚举类.md)
-- [理解克隆与序列化应用](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解克隆与序列化应用.md)
-- ···
-
----
-
-### ⭕ 集合
-
-- [理解集合Collection](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解集合Collection.md)
-- [理解集合Map](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解集合Map.md)
-- [HashMap原理分析](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解HashMap底层实现原理.md)
-- [HashMap为什么是线程不安全的](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解HashMap为什么是线程不安全的.md)
-- [ConcurrentHashMap实现原理](https://github.com/msJavaCoder/msJava/blob/master/docs/Java万岁/Java-基础不牢地动山摇/理解ConcurrentHashMap底层实现原理.md)
-- ···
-
----
-
-
-### 🔐 并发编程
-- [理解线程与死锁](https://github.com/msJavaCoder/msJava/blob/master/docs/并发编程/理解线程与死锁.md)
-- [理解Java中的各种锁](https://github.com/msJavaCoder/msJava/blob/master/docs/并发编程/理解Java中的各种锁.md)
-- [理解ThreadLocal](https://github.com/msJavaCoder/msJava/blob/master/docs/并发编程/理解ThreadLocal.md)
-- [理解synchronized关键字](https://github.com/msJavaCoder/msJava/blob/master/docs/并发编程/理解synchronized关键字.md)
-- [理解线程安全synchronized与ReentrantLock](https://github.com/msJavaCoder/msJava/blob/master/docs/并发编程/理解线程安全synchronized与ReentrantLock.md)
-- [理解线程池](https://github.com/msJavaCoder/msJava/blob/master/docs/并发编程/理解线程池.md)
-- ···
-
----
-
-### 💻 JVM
-- [Java运行时内存划分](https://github.com/msJavaCoder/msJava/blob/master/docs/JVM/Java运行时内存划分.md)
-- [类加载机制](https://github.com/msJavaCoder/msJava/blob/master/docs/JVM/类加载机制.md)
-- [垃圾回收器](https://github.com/msJavaCoder/msJava/blob/master/docs/JVM/垃圾回收器.md)
-- [垃圾回收算法](https://github.com/msJavaCoder/msJava/blob/master/docs/JVM/垃圾回收算法.md)
-- [JVM确认可回收对象的方式](https://github.com/msJavaCoder/msJava/blob/master/docs/JVM/JVM确认可回收对象的方式.md)
-- ···
-
----
-
-
-### 🚏 设计模式
-- [设计模式总结](https://github.com/msJavaCoder/msJava/blob/master/设计模式/设计模式总结.md)
-- [单例模式及Java实现](https://github.com/msJavaCoder/msJava/blob/master/设计模式/单例模式及Java实现.md)
-- [工厂模式及Java实现](https://github.com/msJavaCoder/msJava/blob/master/设计模式/工厂模式及Java实现.md)
-- [抽象工长及Java实现](https://github.com/msJavaCoder/msJava/blob/master/设计模式/抽象工长及Java实现.md)
-- [代理模式及Java实现](https://github.com/msJavaCoder/msJava/blob/master/设计模式/代理模式及Java实现.md)
-- [适配器模式及Java实现](https://github.com/msJavaCoder/msJava/blob/master/设计模式/适配器模式及Java实现.md)
-- ···
-
----
-
-### 🔭 网络
-
-- [理解网络协议分层](https://github.com/msJavaCoder/msJava/blob/master/docs/计算机网络/理解网络协议分层.md)
-- [理解TCP和UDP](https://github.com/msJavaCoder/msJava/blob/master/docs/计算机网络/理解TCP和UDP.md)
-- [理解HTTP与HTTPS](https://github.com/msJavaCoder/msJava/blob/master/docs/计算机网络/理解HTTP与HTTPS.md)
-- ···
-
---
-
-
-### 🌈 面试题
-- [Java核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/Java核心面试题汇总.md)
-- [Spring核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/Spring面试题汇总.md)
-- [SpringMVC核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/SpringMVC面试题汇总.md)
-- [MyBatis核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/MyBatis面试题汇总.md)
-- [SpringBoot核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/SpringBoot面试题汇总.md)
-- [MySQL核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/MySQL面试题汇总.md)
-- [常见算法核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/算法常用面试题汇总.md)
-- [常见JVM核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/JVM面试题汇总.md)
-- [设计模式核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/设计模式常见面试题汇总.md)
-- [消息队列核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/消息队列面试题汇总.md)
-- [分布式核心面试题](https://github.com/msJavaCoder/msJava/blob/master/docs/面试题/分布式框架面试题汇总.md)
-- ···
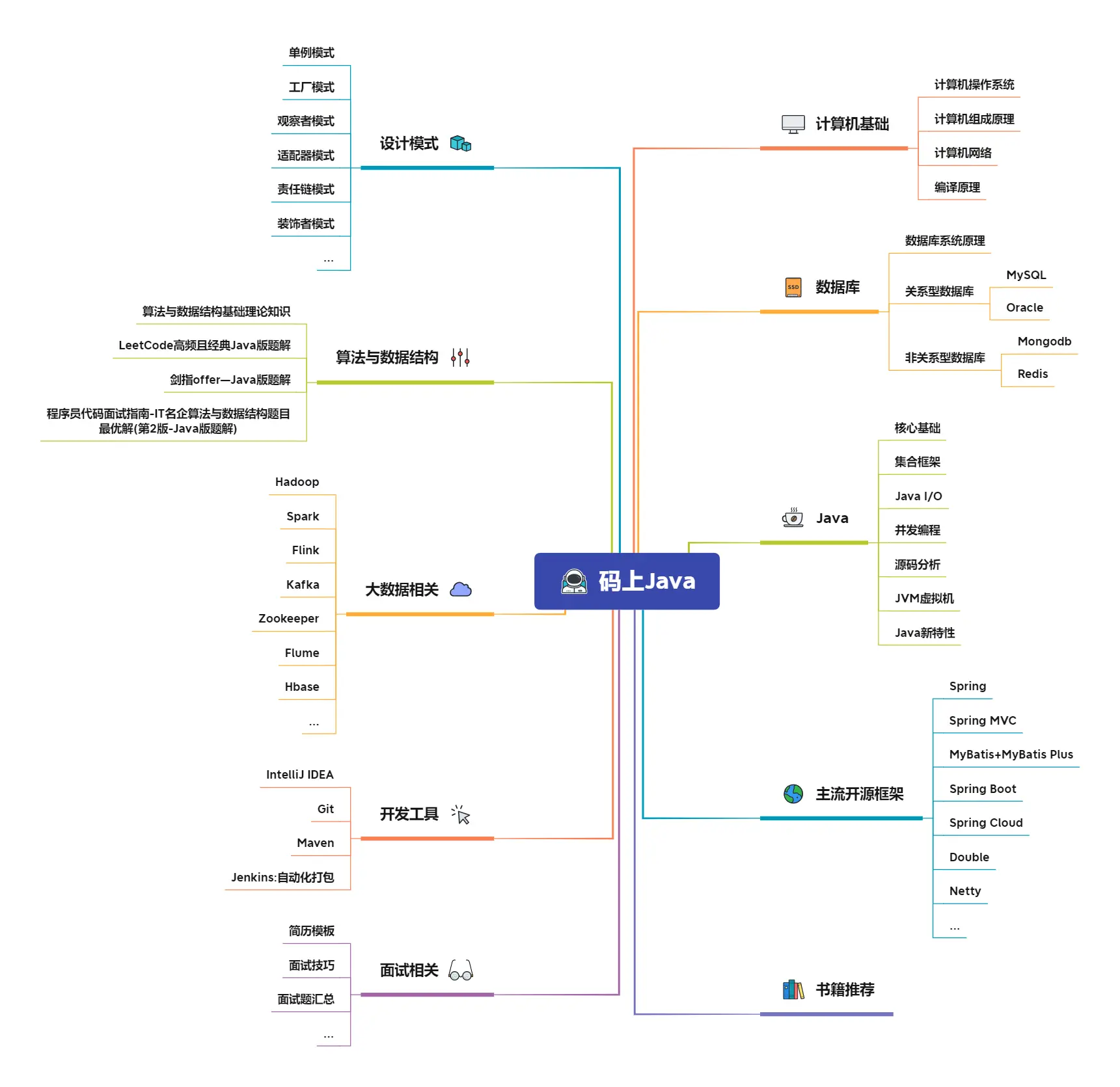
+
---
-### 🚮 踩坑记录
-- [IDEAMaven依赖成功导入但仍然报错找不到包解决方案](https://github.com/msJavaCoder/msJava/blob/master/docs/踩坑记录/IDEAMaven依赖成功导入但仍然报错找不到包解决方案.md)
-- ···
-
-
-
### ☎ 联系作者
-
-> 关注微信订阅号: 码上Java 🔥🔥🔥
-
----
-
+> 关注微信订阅号: 码上Java 🔥🔥🔥
\ No newline at end of file
diff --git a/_coverpage.md b/_coverpage.md
index b25d3e8..c1e5be2 100644
--- a/_coverpage.md
+++ b/_coverpage.md
@@ -1,15 +1,18 @@

-Java后端面试核心知识体系
-愿你的明天永远热泪盈眶 😀
+JAVA后端核心知识体系
+风儿哪儿吹,不要问跟风的人。💯




-
[GitHub](https://github.com/msJavaCoder/msJava)
[开始阅读](#🔥-微信公众号-:-码上java)
+
+
+
+
\ No newline at end of file
diff --git a/_navbar.md b/_navbar.md
index e69de29..795d8fa 100644
--- a/_navbar.md
+++ b/_navbar.md
@@ -0,0 +1,39 @@
+ * Java
+ * [Java核心基础](docs/Java核心基础/README.md)
+ * [Java源码分析](docs/Java源码分析/README.md)
+ * [Java性能优化](docs/Java性能优化/README.md)
+ * [Java并发编程](docs/Java并发编程/README.md)
+ * [Java虚拟机](docs/Java虚拟机/README.md)
+
+ * 主流框架
+ * Spring
+ * SpringMVC
+ * MyBatis
+ * [SpringBoot](docs/SpringBoot/README.md)
+ * SpringCloud
+
+ * 数据库
+ * [MySQL](docs/MySQL/README.md)
+ * [Redis](docs/Redis/README.md)
+
+
+
+ * 数据结构与算法
+ * [排序算法](docs/算法与数据结构/排序算法.md)
+ * [数据结构](docs/算法与数据结构/README.md)
+ * [剑指offer](docs/算法与数据结构/剑指offer题解.md)
+
+ * 计算机基础
+ * 操作系统
+ * 计算机组成原理
+ * 计算机网络
+
+ * 项目实战
+ * 个人博客
+ * wiki知识库
+ * ···
+
+ * [面试题](docs/面试题/README.md)
+
+ * [首页](/)
+
diff --git a/_sidebar.md b/_sidebar.md
index a5cc84c..63bbb3b 100644
--- a/_sidebar.md
+++ b/_sidebar.md
@@ -1,100 +1,47 @@
-* 网络
- * [理解网络协议分层](docs/计算机网络/网络协议分层.md)
- * [理解TCP和UDP](docs/计算机网络/理解TCP和UDP.md)
- * [理解HTTP和HTTPS](docs/计算机网络/理解HTTP与HTTPS.md)
- * ...
-
-* Java核心基础
- * [理解基本数据类型与包装类](docs/Java万岁/Java-基础不牢地动山摇/理解基本数据类型与包装类.md)
- * [理解类与Object](docs/Java万岁/Java-基础不牢地动山摇/理解类与Object.md)
- * [理解泛型与迭代器](docs/Java万岁/Java-基础不牢地动山摇/理解泛型与迭代器.md)
- * [理解Java关键字](docs/Java万岁/Java-基础不牢地动山摇/理解Java关键字.md)
- * [理解String字符串](docs/Java万岁/Java-基础不牢地动山摇/理解String字符串.md)
- * [理解动态代理](docs/Java万岁/Java-基础不牢地动山摇/理解动态代理.md)
- * [理解抽象类与接口](docs/Java万岁/Java-基础不牢地动山摇/理解抽象类与接口.md)
- * [理解异常处理](docs/Java万岁/Java-基础不牢地动山摇/理解异常处理.md)
- * [理解数据结构队列](docs/Java万岁/Java-基础不牢地动山摇/理解数据结构队列.md)
- * [理解内部类与枚举类](docs/Java万岁/Java-基础不牢地动山摇/理解各种内部类和枚举类.md)
- * [理解克隆与序列化应用](docs/Java万岁/Java-基础不牢地动山摇/理解克隆与序列化应用.md)
- * ...
-
-* 集合
- * [理解集合Collection](docs/Java万岁/Java-基础不牢地动山摇/理解集合Collection.md)
- * [理解集合Map](docs/Java万岁/Java-基础不牢地动山摇/理解集合Map.md)
- * [理解HashMap底层实现原理](docs/Java万岁/Java-基础不牢地动山摇/理解HashMap底层实现原理.md)
- * [理解HashMap为什么是线程不安全的](docs/Java万岁/Java-基础不牢地动山摇/理解HashMap为什么是线程不安全的.md)
- * [理解ConcurrentHashMap底层实现原理](docs/Java万岁/Java-基础不牢地动山摇/理解ConcurrentHashMap底层实现原理.md)
- * ...
-
-* Java源码分析
- * [ArrayList源码分析](docs/Java源码分析/ArrayList源码分析.md)
- * [HashMap源码分析](docs/Java源码分析/HashMap源码分析.md)
- * [TreeMap源码分析](docs/Java源码分析/TreeMap源码分析.md)
- * [HashSet与TreeSet源码分析](docs/Java源码分析/HashSet与TreeSet源码分析.md)
- * [LinkedHashMap源码分析](docs/Java源码分析/LinkedHashMap源码分析.md)
- * [ConcurrentHashMap源码分析](docs/Java源码分析/ConcurrentHashMap源码分析.md)
- * ...
-
-* 并发编程
- * [理解线程池](docs/并发编程/理解线程池.md)
- * [理解线程与死锁](docs/并发编程/理解线程与死锁.md)
- * [理解CAS优缺点](docs/并发编程/理解CAS优缺点.md)
- * [理解ThreadLocal](docs/并发编程/理解ThreadLocal.md)
- * [理解synchronized关键字](docs/并发编程/理解synchronized关键字.md)
- * [理解Callable和Runnable的不同](docs/并发编程/理解Callable和Runnable的不同.md)
- * [理解Java中的锁及其特点](docs/并发编程/理解Java中的锁及其特点.md)
- * [理解JVM内存结构与Java内存模型](docs/并发编程/理解JVM内存结构与Java内存模型.md)
- * [理解线程池4种拒绝策略](docs/并发编程/理解线程池4种拒绝策略.md)
- * [理解线程的状态及如何进行转换的](docs/并发编程/理解线程的状态及如何进行转换的.md)
- * [可能会遇到的三类线程安全问题](docs/并发编程/可能会遇到的三类线程安全问题.md)
- * [哪些场景需要额外注意线程安全问题](docs/并发编程/哪些场景需要额外注意线程安全问题.md)
- * [为什么说本质上实现线程的方法只有一种](docs/并发编程/为什么说本质上实现线程的方法只有一种.md)
- * [理解线程安全synchronized与ReentrantLock](docs/并发编程/理解线程安全synchronized与ReentrantLock.md)
- * ...
-
-* JVM
- * [垃圾回收器](docs/JVM/垃圾回收器.md)
- * [垃圾回收算法](docs/JVM/垃圾回收算法.md)
- * [类加载机制](docs/JVM/类加载机制.md)
- * [Java运行时内存划分](docs/JVM/Java运行时内存划分.md)
- * [JVM确认可回收对象的方式](docs/JVM/JVM确认可回收对象的方式.md)
- * ...
-
-* 数据库
- * [理解MySQL基础概念](docs/MySQL/MySQL基础概念.md)
- * [教你如何使用索引](docs/MySQL/如何使用索引.md)
- * [什么情况下索引会失效](docs/MySQL/什么情况下索引失效.md)
- * [什么时候不需要创建索引](docs/MySQL/什么时候不需要创建索引.md)
- * [常见SQL优化方式](docs/MySQL/常见SQL优化方式.md)
- * [浅谈MySQL的优化方案](docs/MySQL/浅谈MySQL的优化方案.md)
- * [B树与B+树详谈](docs/MySQL/B树与B+树详谈.md)
- * [Hash索引与B+树索引的区别](docs/MySQL/Hash索引与B+树索引的区别.md)
- * [如何使用EXPLAIN查看执行计划](docs/MySQL/如何使用EXPLAIN查看执行计划.md)
- * ...
-
-* SpringBoot专栏
- * ...
-
-
-* SpringBoot常用技术整合
- * [SpringBoot-MyBatisPlus](docs/SpringBoot/基于SpringBoot集成Mybatis-Plus实现代码生成器.md)
- * ...
-
-* 面试题
- * [Java核心面试题汇总](docs/面试题/Java核心面试题汇总.md)
- * [Spring核心面试题汇总](docs/面试题/Spring面试题汇总.md)
- * [SpringBoot核心面试题汇总](docs/面试题/SpringBoot面试题汇总.md)
- * [SpringMVC核心面试题汇总](docs/面试题/SpringMVC面试题汇总.md)
- * [MyBatis核心面试题汇总](docs/面试题/MyBatis面试题汇总.md)
- * [MySQL面试题汇总](docs/面试题/MySQL面试题汇总.md)
- * [算法常用面试题汇总](docs/面试题/算法常用面试题汇总.md)
- * [JVM面试题汇总](docs/面试题/JVM面试题汇总.md)
- * [设计模式常见面试题汇总](docs/面试题/设计模式常见面试题汇总.md)
- * [消息队列面试题汇总](docs/面试题/消息队列面试题汇总.md)
- * [分布式框架面试题汇总](docs/面试题/分布式框架面试题合集.md)
- * ...
+
+* [**📕 数据结构与算法**](docs/算法与数据结构/README.md)
+
-* 踩坑记录
- * [Maven依赖成功导入但仍然报错找不到包解决方案](docs/踩坑记录/IDEAMaven依赖成功导入但仍然报错找不到包解决方案.md)
- * ...
+---
+
+* [**💦 Java核心基础**](docs/Java核心基础/README.md)
+
+---
+
+* [**🙈 Java源码分析**](docs/Java源码分析/README.md)
+
+---
+
+* [**🐯 Java并发编程**](docs/Java并发编程/README.md)
+
+---
+
+* [**🐷 Java虚拟机**](docs/Java虚拟机/README.md)
+
+---
+
+* [**🌱 SpringBoot**](docs/SpringBoot/README.md)
+
+
+---
+
+* [**📚 MySQL**](docs/MySQL/README.md)
+
+---
+
+* **🌀 Redis**
+
+
+---
+
+* [**📑 设计模式**](docs/设计模式/README.md)
+
+---
+
+* [**👀 面试题**](docs/面试题/README.md)
+
+---
+
+* **🔨 杂谈**
+---
diff --git "a/docs/JVM/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md" "b/docs/JVM/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md"
deleted file mode 100644
index 7d209ae..0000000
--- "a/docs/JVM/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md"
+++ /dev/null
@@ -1,17 +0,0 @@
-# 如何确定垃圾
-
-+ 引用计数法
-
-在Java中如果要操作对象,就必须先获取该对象的引用,因此可以通过引用计数法来判断一个对象是否可以被回收。在为一个对象添加一个引用时,引用计数器就加1;为对象删除一个引用时,引用计数器就减1;如果一个对象的引用计数为0,则说明该对象没有被引用,可以回收。**优点是垃圾回收比较及时,实时性比较高,只要对象计数器为 0,则可以直接进行回收操作;而缺点是无法解决循环引用的问题。**
-
-+ 可达性分析
-
-以一系列GC ROOTS的点作为起点向下搜索,当一个对象到任何GC ROOTS都没有引用链相连时,说明该对象可以回收。
-
-在 Java 中可以作为 **CG Roots 的对象**,主要包含以下几个:
-
-1. 所有被同步锁持有的对象,比如被 synchronize 持有的对象;
-2. 字符串常量池里的引用(String Table);
-3. 类型为引用类型的静态变量;
-4. 虚拟机栈中引用对象;
-5. 本地方法栈中的引用对象。
\ No newline at end of file
diff --git "a/docs/JVM/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md" "b/docs/JVM/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md"
deleted file mode 100644
index b99cfd8..0000000
--- "a/docs/JVM/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md"
+++ /dev/null
@@ -1,28 +0,0 @@
-# JVM运行内存区域
-
-> JVM内存区域分为线程私有区域(程序计数器、虚拟机栈、本地方法区),线程共享区域(堆内存、方法区)和直接内存。
-
- -
-+ 程序计数器
-
-程序计数器是一块很小的内存空间,用于存储当前运行的线程所执行的字节码的行号指令,每个运行中的线程都有一个独立的程序计数器,在方法正在执行时,该方法的程序计数器记录的是实时虚拟机字节码指令的地址;如果该方法执行的是Native方法,则程序计数器的值为空。
-
-+ 虚拟机栈
-
-虚拟机栈是描述Java方法的执行过程的内存模型,它在当前栈帧存储了局部变量表、操作数栈、动态链接、方法出口等信息。同时,栈帧用来存储部分运行时数据及其数据结构,处理动态链接方法的返回值和异常分派。
-
-+ 本地方法区
-
-本地方法区和虚拟机栈作用类似,区别就是本地方法栈是为Native方法服务,而虚拟机栈是为了Java方法服务。
-
-+ 堆内存
-
-在JVM运行过程中创建的对象和产生的数据都被存储在堆中,堆是被线程共享的内存区域,也是垃圾收集器进行垃圾回首的最主要的内存区域。
-
-+ 方法区
-
-方法区用于存储常量、静态变量、类信息、即时编译器编译后的机器码、运行时常量等数据。
-
-
-
diff --git "a/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/README.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/README.md"
new file mode 100644
index 0000000..94e0a88
--- /dev/null
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/README.md"
@@ -0,0 +1,17 @@
+# Java并发编程
+ * [为什么说本质上实现线程的方法只有一种](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
+ * [可能会遇到的三类线程安全问题](docs/Java并发编程/可能会遇到的三类线程安全问题.md)
+ * [哪些场景需要额外注意线程安全问题](docs/Java并发编程/哪些场景需要额外注意线程安全问题.md)
+ * [理解Callable和Runnable的不同](docs/Java并发编程/理解Callable和Runnable的不同.md)
+ * [理解CAS优缺点](docs/Java并发编程/理解CAS优缺点.md)
+ * [理解Java中的各种锁](docs/Java并发编程/理解Java中的各种锁.md)
+ * [理解Java中的锁及其特点](docs/Java并发编程/理解Java中的锁及其特点.md)
+ * [理解JVM内存结构与Java内存模型](docs/Java并发编程/理解JVM内存结构与Java内存模型.md)
+ * [理解synchronized关键字](docs/Java并发编程/理解synchronized关键字.md)
+ * [理解ThreadLocal](docs/Java并发编程/理解ThreadLocal.md)
+ * [理解线程与死锁](docs/Java并发编程/理解线程与死锁.md)
+ * [理解线程安全synchronized与ReentrantLock](docs/Java并发编程/理解线程安全synchronized与ReentrantLock.md)
+ * [理解线程池](docs/Java并发编程/理解线程池.md)
+ * [理解线程池4种拒绝策略](docs/Java并发编程/理解线程池4种拒绝策略.md)
+ * [理解线程的状态及如何进行转换的](docs/Java并发编程/理解线程的状态及如何进行转换的.md)
+ * [第2章Java并发机制的底层原理](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
diff --git "a/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/_sidebar.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/_sidebar.md"
new file mode 100644
index 0000000..5b75b0c
--- /dev/null
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/_sidebar.md"
@@ -0,0 +1,17 @@
+* **👉 Java并发编程** [↩](/README)
+ * [为什么说本质上实现线程的方法只有一种](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
+ * [可能会遇到的三类线程安全问题](docs/Java并发编程/可能会遇到的三类线程安全问题.md)
+ * [哪些场景需要额外注意线程安全问题](docs/Java并发编程/哪些场景需要额外注意线程安全问题.md)
+ * [理解Callable和Runnable的不同](docs/Java并发编程/理解Callable和Runnable的不同.md)
+ * [理解CAS优缺点](docs/Java并发编程/理解CAS优缺点.md)
+ * [理解Java中的各种锁](docs/Java并发编程/理解Java中的各种锁.md)
+ * [理解Java中的锁及其特点](docs/Java并发编程/理解Java中的锁及其特点.md)
+ * [理解JVM内存结构与Java内存模型](docs/Java并发编程/理解JVM内存结构与Java内存模型.md)
+ * [理解synchronized关键字](docs/Java并发编程/理解synchronized关键字.md)
+ * [理解ThreadLocal](docs/Java并发编程/理解ThreadLocal.md)
+ * [理解线程与死锁](docs/Java并发编程/理解线程与死锁.md)
+ * [理解线程安全synchronized与ReentrantLock](docs/Java并发编程/理解线程安全synchronized与ReentrantLock.md)
+ * [理解线程池](docs/Java并发编程/理解线程池.md)
+ * [理解线程池4种拒绝策略](docs/Java并发编程/理解线程池4种拒绝策略.md)
+ * [理解线程的状态及如何进行转换的](docs/Java并发编程/理解线程的状态及如何进行转换的.md)
+ * [第2章Java并发机制的底层原理](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
\ No newline at end of file
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
index 06f4100..aaa6efc 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
@@ -1,4 +1,4 @@
-# 为什么说本质上实现线程的方法只有一种?
+# 👉 为什么说本质上实现线程的方法只有一种?
> 在本课时我们主要学习为什么说本质上只有一种实现线程的方式?实现 Runnable 接口究竟比继承 Thread 类实现线程好在哪里?
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
index 65e0584..7a27b33 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
@@ -1,3 +1,5 @@
+# 👉 可能会遇到的三类线程安全问题
+
>本文我们一起学习在实际工作中可能会遇到的三类线程安全问题。
## 什么是线程安全
要想弄清楚有哪 3 类线程安全问题,首先需要了解什么是线程安全,线程安全经常在工作中被提到,比如:你的对象不是线程安全的,你的线程发生了安全错误,虽然线程安全经常被提到,但我们可能对线程安全并没有一个明确的定义。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
index 25ee63f..a30ac4f 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
@@ -1,7 +1,6 @@
-> 本文我们一起学习在实际开发中哪些场景需要额外注意线程安全问题?
-
-
+# 👉 哪些场景需要额外注意线程安全问题
+> 本文我们一起学习在实际开发中哪些场景需要额外注意线程安全问题?
## 1.访问共享变量或资源
第一种场景是访问共享变量或共享资源的时候,典型的场景有访问共享对象的属性,访问 static 静态变量,访问共享的缓存,等等。因为这些信息不仅会被一个线程访问到,还有可能被多个线程同时访问,那么就有可能在并发读写的情况下发生线程安全问题。比如我们上一课时讲过的多线程同时 i++ 的例子:
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
index 62d4d91..1c3a819 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
@@ -1,4 +1,4 @@
-# CAS有很多优点,但它的缺点呢?
+# 👉 CAS有很多优点,但它的缺点呢?
> 本文我们一起学习探讨CAS的缺点。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
index 33bc68b..5d0f976 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
@@ -1,5 +1,5 @@
-# Callable和Runnable的不同?
+# 👉 Callable和Runnable的不同?
> 本文我们一起学习 Callable 和 Runnable 的不同。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
similarity index 97%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
index d9c5bd5..7c8fcff 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
@@ -1,5 +1,4 @@
-
-# 不要在混淆JVM内存结构与Java内存模型了!
+# 👉 不要在混淆JVM内存结构与Java内存模型了!
> 本文我们一起学习什么是Java内存模型。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
index 03a4f68..2a28a65 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
@@ -1,4 +1,4 @@
-## 理解Java中的各种锁
+# 👉 理解Java中的各种锁
如果说快速理解多线程有什么捷径的话,那本文介绍的各种锁无疑是其中之一,它不但为我们开发多线程程序提供理论支持,还是面试中经常被问到的核心面试题之一。因此下面就让我们一起深入地学习一下这些锁吧。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
index 0adcda7..657c578 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
@@ -1,4 +1,4 @@
-# Java中哪几种锁?分别有什么特点?
+# 👉 Java中哪几种锁?分别有什么特点?
> 本文中我们一起学习Java中锁的分类及其特点。
锁是用来控制多线程访问共享资源的方式,一般的讲,一个锁能够防止多个线程同时访问共享资源。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
index b78f9b6..fc69799 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
@@ -1,4 +1,4 @@
-## 理解ThreadLocal
+# 👉 理解ThreadLocal
**什么是 ThreadLocal?**
ThreadLocal 诞生于 JDK 1.2,用于解决多线程间的数据隔离问题。也就是说 ThreadLocal 会为每一个线程创建一个单独的变量副本。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
index 779eda2..8b0626b 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
@@ -1,4 +1,4 @@
-# synchronized关键字原理
+# 👉 synchronized关键字原理
众所周知 `synchronized` 关键字是解决并发问题常用解决方案,有以下三种使用方式:
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
index 8637caa..68ce72c 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
@@ -1,4 +1,4 @@
-## 理解线程与死锁
+# 👉 理解线程与死锁
### 线程介绍
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
index 393737a..92af496 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
@@ -1,4 +1,4 @@
-## 理解线程安全synchronized与ReentrantLock
+# 👉 理解线程安全synchronized与ReentrantLock
前面我们介绍了很多关于多线程的内容,在多线程中有一个很重要的课题需要我们攻克,那就是线程安全问题。线程安全问题指的是在多线程中,各线程之间因为同时操作所产生的数据污染或其他非预期的程序运行结果。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md"
similarity index 100%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md"
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
index c9a9297..90500ee 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
@@ -1,10 +1,9 @@
-> 本文我们一起学习线程池有哪 4 种默认的拒绝策略。
+# 👉 线程池的拒绝策略
-# 线程池的拒绝策略
+> 本文我们一起学习线程池有哪 4 种默认的拒绝策略。
若线程池中的核心线程数被用完且阻塞队列已排满,则此时线程池的资源已耗尽,线程池将没有足够的线程资源执行新的任务。为了保证操作系统的安全,线程池将通过拒绝策略处理新添加的线程任务。
-
## 1. AbortPolicy
第一种拒绝策略是 `AbortPolicy`,这种拒绝策略在拒绝任务时,会直接抛出一个类型为 RejectedExecutionException的RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
index 3618b62..1612d62 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
@@ -1,3 +1,4 @@
+# 👉 理解线程的状态及如何进行转换的
> 本文我们一起学习线程的状态有哪些以及它们之间是如何进行转换的?
线程(Thread)是并发编程的基础,也是程序执行的最小单元,它依托进程而存在。一个进程中可以包含多个线程,多线程可以共享一块内存空间和一组系统资源,因此线程之间的切换更加节省资源、更加轻量化,也因此被称为轻量级的进程。
diff --git "a/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md"
similarity index 100%
rename from "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md"
diff --git "a/docs/Java\345\274\200\345\217\221\350\247\204\350\214\203/Java\345\274\200\345\217\221\346\211\213\345\206\214\345\265\251\345\261\261\347\211\210.md" "b/docs/Java\345\274\200\345\217\221\350\247\204\350\214\203/Java\345\274\200\345\217\221\346\211\213\345\206\214\345\265\251\345\261\261\347\211\210.md"
new file mode 100644
index 0000000..f67b914
--- /dev/null
+++ "b/docs/Java\345\274\200\345\217\221\350\247\204\350\214\203/Java\345\274\200\345\217\221\346\211\213\345\206\214\345\265\251\345\261\261\347\211\210.md"
@@ -0,0 +1,255 @@
+# 👉 Java开发手册 嵩山版
+
+| 版本 | 制定 | 更新日期 | 备注 |
+| :---: | :----------------------------: | :--------: | :------------------------: |
+| 1.7.0 | 阿里巴巴与全球 Java 社区开发者 | 2020.08.03 | 嵩山版,首次发布前后端规约
+
+ ## 一、 编程规约
+
+### (一) 命名风格
+
+1. **【强制】代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。**
+
+ > **反例:_name / __name / $name / name_ / name$ / name__**
+
+2. **【强制】所有编程相关的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。**
+
+ **说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。注意,纯拼音命名方式更要避免采用。**
+
+ > **正例:ali / alibaba / taobao / cainiao/ aliyun/ youku / hangzhou 等国际通用的名称,可视同英文。**
+ >
+ > **反例:DaZhePromotion [打折] / getPingfenByName() [评分] / String fw[福娃] / int 某变量 = 3**
+
+3. **【强制】代码和注释中都要避免使用任何语言的种族歧视性词语。**
+
+ > **正例:日本人 / 印度人 / blockList / allowList / secondary**
+ >
+ > **反例:RIBENGUIZI / Asan / blackList / whiteList / slave**
+
+4. **【强制】类名使用 UpperCamelCase 风格,但以下情形例外:DO / BO / DTO / VO / AO / PO / UID 等。**
+
+ > **正例:ForceCode / UserDO / HtmlDTO / XmlService / TcpUdpDeal / TaPromotion**
+ >
+ > **反例:forcecode / UserDo / HTMLDto / XMLService / TCPUDPDeal / TAPromotion**
+
+5. **【强制】方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格。**
+
+ > **正例: localValue / getHttpMessage() / inputUserId**
+
+6. **【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。**
+
+ > **正例:MAX_STOCK_COUNT / CACHE_EXPIRED_TIME 反例:MAX_COUNT / EXPIRED_TIME**
+
+7. **【强制】抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类 命名以它要测试的类的名称开始,以 Test 结尾。**
+
+8. **【强制】类型与中括号紧挨相连来表示数组。 正例:定义整形数组 int[] arrayDemo。**
+
+ > **反例:在 main 参数中,使用 String args[]来定义。**
+
+9. **【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列 化错误。**
+
+ **说明:在本文 MySQL 规约中的建表约定第一条,表达是与否的变量采用 is_xxx 的命名方式,所以,需要 在设置从 is_xxx 到 xxx 的映射关系。**
+
+ > **反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时 候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。**
+
+10. **【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用 单数形式,但是类名如果有复数含义,类名可以使用复数形式。**
+
+ > **正例:应用工具类包名为 com.alibaba.ei.kunlun.aap.util、类名为 MessageUtils(此规则参考 spring 的 框架结构)**
+
+11. **【强制】避免在子父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名, 使可理解性降低。**
+
+ **说明:子类、父类成员变量名相同,即使是 public 类型的变量也能够通过编译,另外,局部变量在同一方 法内的不同代码块中同名也是合法的,这些情况都要避免。对于非 setter/getter 的参数名称也要避免与成 员变量名称相同。**
+
+ ```java
+ 反例:
+ public class ConfusingName {
+ public int stock;
+ // 非 setter/getter 的参数名称,不允许与本类成员变量同名
+ public void get(String alibaba) {
+ if (condition) {
+ final int money = 666;
+ // ...
+ }
+ for (int i = 0; i < 10; i++) {
+ // 在同一方法体中,不允许与其它代码块中的 money 命名相同
+ final int money = 15978;
+ // ...
+ }
+ }
+ }
+ class Son extends ConfusingName {
+ // 不允许与父类的成员变量名称相同
+ public int stock;
+ }
+ ```
+
+12. **【强制】杜绝完全不规范的缩写,避免望文不知义。**
+
+ > **反例:AbstractClass“缩写”成 AbsClass;condition“缩写”成 condi;Function 缩写”成 Fu,此类 随意缩写严重降低了代码的可阅读性。**
+
+13. **【推荐】为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组 合来表达。**
+
+ > **正例:对某个对象引用的 volatile 字段进行原子更新的类名为 AtomicReferenceFieldUpdater。**
+ >
+ > **反例:常见的方法内变量为 int a;的定义方式**。
+
+14. **【推荐】在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。**
+
+ > **正例:startTime / workQueue / nameList / TERMINATED_THREAD_COUNT**
+ >
+ > **反例:startedAt / QueueOfWork / listName / COUNT_TERMINATED_THREAD**
+
+15. **【推荐】如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式。**
+
+ **说明:将设计模式体现在名字中,有利于阅读者快速理解架构设计理念。**
+
+ > 正例: public class OrderFactory;
+ >
+ > public class LoginProxy;
+ >
+ > public class ResourceObserver;
+
+16. **【推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁 性,并加上有效的 Javadoc 注释。尽量不要在接口里定义变量,如果一定要定义变量,确定 与接口方法相关,并且是整个应用的基础常量。**
+
+ > 正例:接口方法签名 void commit(); 接口基础常量 String COMPANY = "alibaba";
+ >
+ > 反例:接口方法定义 public abstract void f();
+
+ **说明:JDK8 中接口允许有默认实现,那么这个 default 方法,是对所有实现类都有价值的默认实现。**
+
+17. **接口和实现类的命名有两套规则:**
+
+ **1)【强制】对于 Service 和 DAO 类,基于 SOA 的理念,暴露出来的服务一定是接口,内部的实现类用 Impl 的后缀与接口区别。**
+
+ > **正例:CacheServiceImpl 实现 CacheService 接口。**
+
+ **2)【推荐】如果是形容能力的接口名称,取对应的形容词为接口名(通常是–able 的形容词)。**
+
+ > **正例:AbstractTranslator 实现 Translatable 接口。**
+
+18. **【参考】枚举类名带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。**
+
+ **说明:枚举其实就是特殊的常量类,且构造方法被默认强制是私有。**
+
+ > 正例:枚举名字为 ProcessStatusEnum 的成员名称:SUCCESS / UNKNOWN_REASON。
+
+19. **【参考】各层命名规约:**
+
+ **A) Service/DAO 层方法命名规约**
+
+ **1) 获取单个对象的方法用 get 做前缀。**
+
+ **2) 获取多个对象的方法用 list 做前缀,复数结尾,如:listObjects。**
+
+ **3) 获取统计值的方法用 count 做前缀。**
+
+ **4) 插入的方法用 save/insert 做前缀。**
+
+ **5) 删除的方法用 remove/delete 做前缀。**
+
+ **6) 修改的方法用 update 做前缀。**
+
+ **B) 领域模型命名规约 Java 开发手册 4/59**
+
+ **1) 数据对象:xxxDO,xxx 即为数据表名。**
+
+ **2) 数据传输对象:xxxDTO,xxx 为业务领域相关的名称。**
+
+ **3) 展示对象:xxxVO,xxx 一般为网页名称。**
+
+ **4) POJO 是 DO/DTO/BO/VO 的统称,禁止命名成 xxxPOJO。**
+
+### (二) 常量定义
+
+1. **【强制】不允许任何魔法值(即未经预先定义的常量)直接出现在代码中。**
+
+ > **反例: // 本例中,开发者 A 定义了缓存的 key,然后开发者 B 使用缓存时少了下划线,即 key 是"Id#taobao"+tradeId,导致 出现故障**
+ >
+ > **String key = "Id#taobao_" + tradeId; cache.put(key, value);**
+
+2. **【强制】在 long 或者 Long 赋值时,数值后使用大写字母 L,不能是小写字母 l,小写容易跟 数字混淆,造成误解。**
+
+ > **说明:Long a = 2l; 写的是数字的 21,还是 Long 型的 2?**
+
+3. 【**推荐】不要使用一个常量类维护所有常量,要按常量功能进行归类,分开维护。**
+
+ **说明:大而全的常量类,杂乱无章,使用查找功能才能定位到修改的常量,不利于理解,也不利于维护。**
+
+ > **正例:缓存相关常量放在类 CacheConsts 下;系统配置相关常量放在类 SystemConfigConsts 下。**
+
+4. **【推荐】常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包 内共享常量、类内共享常量。**
+
+ **1) 跨应用共享常量:放置在二方库中,通常是 client.jar 中的 constant 目录下。**
+
+ **2) 应用内共享常量:放置在一方库中,通常是子模块中的 constant 目录下。**
+
+ > **反例:易懂变量也要统一定义成应用内共享常量,两位工程师在两个类中分别定义了“YES”的变量:**
+ >
+ > **类 A 中:public static final String YES = "yes";**
+ >
+ > **类 B 中:public static final String YES = "y"; A.YES.equals(B.YES),预期是 true,但实际返回为 false,导致线上问题。**
+
+ **3) 子工程内部共享常量:即在当前子工程的 constant 目录下。**
+
+ **4) 包内共享常量:即在当前包下单独的 constant 目录下。**
+
+ **5) 类内共享常量:直接在类内部 private static final 定义。**
+
+5.
+
+### (三) 代码格式
+
+### (四) OOP 规约
+
+### (五) 日期时间
+
+### (六) 集合处理
+
+### (七) 并发处理
+
+### (八) 控制语句
+
+### (九) 注释规约
+
+### (十) 前后端规约
+
+### (十一) 其他
+
+## 二、异常日志
+
+### (一) 错误码
+
+### (二) 异常处理
+
+### (三) 日志规约
+
+## 三、单元测试
+
+## 四、安全规约
+
+## 五、MySQL 数据库
+
+### (一) 建表规约
+
+### (二) 索引规约
+
+### (三) SQL 语句
+
+### (四) ORM 映射
+
+## 六、工程结构
+
+### (一) 应用分层
+
+### (二) 二方库依赖
+
+### (三) 服务器
+
+## 七、设计规约
+
+# 附 1:专有名词解释
+
+# 附 2:错误码列表
+
+
+
diff --git "a/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/README.md" "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/README.md"
new file mode 100644
index 0000000..47f4eec
--- /dev/null
+++ "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/README.md"
@@ -0,0 +1,3 @@
+# Java性能优化
+
+* [常见Java代码优化法则](docs/Java并发编程/常见Java代码优化法则.md)
diff --git "a/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/_sidebar.md" "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/_sidebar.md"
new file mode 100644
index 0000000..828be2b
--- /dev/null
+++ "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/_sidebar.md"
@@ -0,0 +1,3 @@
+* **👉 Java性能优化** [↩](/README)
+ * [常见Java代码优化法则](docs/Java性能优化/常见Java代码优化法则.md)
+
\ No newline at end of file
diff --git "a/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/\345\270\270\350\247\201Java\344\273\243\347\240\201\344\274\230\345\214\226\346\263\225\345\210\231.md" "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/\345\270\270\350\247\201Java\344\273\243\347\240\201\344\274\230\345\214\226\346\263\225\345\210\231.md"
new file mode 100644
index 0000000..2eb7417
--- /dev/null
+++ "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/\345\270\270\350\247\201Java\344\273\243\347\240\201\344\274\230\345\214\226\346\263\225\345\210\231.md"
@@ -0,0 +1,89 @@
+# 👉 常见Java代码优化法则
+
+## 1.使用局部变量可避免在堆上分配
+由于堆资源是多线程共享的,是垃圾回收器工作的主要区域,过多的对象会造成 GC 压力。可以通过局部变量的方式,将变量在栈上分配。这种方式变量会随着方法执行的完毕而销毁,能够减轻 GC 的压力。
+
+## 2.削弱变量的作用范围
+注意变量的作用范围,尽量减少对象的创建。如下面的代码,变量 a 每次进入方法都会创建,可以将它移动到 if 语句内部。
+
+## 3.使用类名方式访问静态变量
+有的同学习惯使用对象访问静态变量,这种方式多了一步寻址操作,需要先找到变量对应的类,再找到类对应的变量。
+
+## 4.字符串拼接不要使用 ”+”
+字符串拼接,使用 `StringBuilder `或者` StringBuffer`,不要使用 + 号。
+
+## 5.重写对象的`HashCode`,不要简单地返回固定值
+开发时重写 `HashCode` 和`Equals` 方法时,会把 `HashCode `的值返回固定的 0,而这样做是不恰当的。
+
+当这些对象存入 `HashMap` 时,性能就会非常低,因为 `HashMap `是通过 `HashCode` 定位到 Hash 槽,有冲突的时候,才会使用链表或者红黑树组织节点。固定地返回 0,相当于把 Hash 寻址功能给废除了。
+
+## 6.`HashMap `等集合初始化的时候,尽量指定初始值大小
+通过指定初始值大小可减少扩容造成的性能损耗。
+
+## 7.遍历`Map` 的时候,使用 `EntrySet` 方法
+使用 EntrySet 方法,可以直接返回 set 对象,直接拿来用即可;而使用 KeySet 方法,获得的是key 的集合,需要再进行一次 get 操作,多了一个操作步骤。所以更推荐使用 EntrySet 方式遍历 Map。
+
+## 8.不要在多线程下使用同一个 Random
+Random 类的 seed 会在并发访问的情况下发生竞争,造成性能降低,建议在多线程环境下使用 `ThreadLocalRandom` 类。
+
+> 在 Linux 上,通过加入 JVM 配置 -Djava.security.egd=file:/dev/./urandom,使用 urandom 随机生成器,在进行随机数获取时,速度会更快。
+
+## 9.自增推荐使用 LongAddr
+自增运算可以通过 synchronized 和 volatile 的组合,或者也可以使用原子类(比如 AtomicLong)。
+
+后者的速度比前者要高一些,AtomicLong 使用 CAS 进行比较替换,在线程多的情况下会造成过多无效自旋,所以可以使用 LongAdder 替换 AtomicLong 进行进一步的性能提升。
+
+## 10.不要使用异常控制程序流程
+异常,是用来了解并解决程序中遇到的各种不正常的情况,它的实现方式比较昂贵,比平常的条件判断语句效率要低很多。
+
+这是因为异常在字节码层面,需要生成一个如下所示的异常表(Exception table),多了很多判断步骤。
+
+## 11.不要在循环中使用 try catch
+道理与上面类似,很多文章介绍,不要把异常处理放在循环里,而应该把它放在最外层,但实际测试情况表明这两种方式性能相差并不大。
+
+既然性能没什么差别,那么就推荐根据业务的需求进行编码。比如,循环遇到异常时,不允许中断,也就是允许在发生异常的时候能够继续运行下去,那么异常就只能在 for 循环里进行处理。
+
+## 12.不要捕捉 RuntimeException
+Java 异常分为两种,一种是可以通过预检查机制避免的 RuntimeException;另外一种就是普通异常。
+
+其中,RuntimeException 不应该通过 catch 语句去捕捉,而应该使用编码手段进行规避。
+
+## 13.合理使用 PreparedStatement
+PreparedStatement 使用预编译对 SQL 的执行进行提速,大多数数据库都会努力对这些能够复用的查询语句进行预编译优化,并能够将这些编译结果缓存起来。
+
+这样等到下次用到的时候,就可以很快进行执行,也就少了一步对 SQL 的解析动作。
+
+PreparedStatement 还能提高程序的安全性,能够有效防止 SQL 注入。
+
+但如果你的程序每次 SQL 都会变化,不得不手工拼接一些数据,那么 PreparedStatement 就失去了它的作用,反而使用普通的 Statement 速度会更快一些。
+
+## 14.日志打印的注意事项
+ debug 输出一些调试信息,然后在线上关掉它。
+
+## 15.减少事务的作用范围
+如果的程序使用了事务,那一定要注意事务的作用范围,尽量以最快的速度完成事务操作。这是因为,事务的隔离性是使用锁实现的。
+
+## 16.使用位移操作替代乘除法
+计算机是使用二进制表示的,位移操作会极大地提高性能。
+
+- `<<` 左移相当于乘以 2;
+- `<<` 右移相当于除以 2;
+- `>>>`无符号右移相当于除以 2,但它会忽略符号位,空位都以 0 补齐。
+
+## 17.不要打印大集合或者使用大集合的 toString 方法
+有的开发喜欢将集合作为字符串输出到日志文件中,这个习惯是非常不好的。
+
+拿 ArrayList 来说,它需要遍历所有的元素来迭代生成字符串。在集合中元素非常多的情况下,这不仅会占用大量的内存空间,执行效率也非常慢
+
+## 18.尽量少在程序中使用反射
+反射的功能很强大,但它是通过解析字节码实现的,性能就不是很理想。
+
+现实中有很多对反射的优化方法,比如把反射执行的过程(比如 Method)缓存起来,使用复用来加快反射速度。
+
+Java 7.0 之后,加入了新的包 java.lang.invoke,同时加入了新的 JVM 字节码指令 invokedynamic,用来支持从 JVM 层面,直接通过字符串对目标方法进行调用。
+
+如果你对性能有非常苛刻的要求,则使用 invoke 包下的 MethodHandle 对代码进行着重优化,但它的编程不如反射方便,在平常的编码中,反射依然是首选。
+
+## 19.正则表达式可以预先编译,加快速度
+Java 的正则表达式需要先编译再使用。
+
diff --git "a/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/README.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/README.md"
new file mode 100644
index 0000000..a816816
--- /dev/null
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/README.md"
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git "a/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/_sidebar.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/_sidebar.md"
new file mode 100644
index 0000000..fae09b2
--- /dev/null
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/_sidebar.md"
@@ -0,0 +1,20 @@
+* **👉 Java核心基础** [↩](/README)
+ * [理解Java关键字](docs/Java核心基础/理解Java关键字.md)
+ * [理解String字符串](docs/Java核心基础/理解String字符串.md)
+ * [理解基本数据类型与包装类](docs/Java核心基础/理解基本数据类型与包装类.md)
+ * [理解各种内部类和枚举类](docs/Java核心基础/理解各种内部类和枚举类.md)
+ * [理解动态代理](docs/Java核心基础/理解动态代理.md)
+ * [理解克隆与序列化应用](docs/Java核心基础/理解克隆与序列化应用.md)
+ * [理解异常处理](docs/Java核心基础/理解异常处理.md)
+ * [理解抽象类与接口](docs/Java核心基础/理解抽象类与接口.md)
+ * [理解泛型与迭代器](docs/Java核心基础/理解泛型与迭代器.md)
+ * [理解浅克隆和深克隆](docs/Java核心基础/理解浅克隆和深克隆.md)
+ * [理解类与Object](docs/Java核心基础/理解类与Object.md)
+ * [理解集合Collection](docs/Java核心基础/理解集合Collection.md)
+ * [理解集合Map](docs/Java核心基础/理解集合Map.md)
+ * [理解Java中的各种锁](docs/Java核心基础/理解Java中的各种锁.md)
+ * [理解HashMap底层实现原理](docs/Java核心基础/理解HashMap底层实现原理.md)
+ * [理解HashMap为什么是线程不安全的](docs/Java核心基础/理解HashMap为什么是线程不安全的.md)
+ * [理解ConcurrentHashMap底层实现原理](docs/Java核心基础/理解ConcurrentHashMap底层实现原理.md)
+ * [理解数据结构队列](docs/Java核心基础/理解数据结构队列.md)
+
\ No newline at end of file
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
similarity index 91%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
index 659c6f0..6ca3096 100644
--- "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
@@ -1,6 +1,6 @@
-## 理解基本数据类型与包装类
+# 理解基本数据类型与包装类
-### 基本数据类型
+## 基本数据类型
Java 基本数据按类型可以分为四大类:布尔型、整数型、浮点型、字符型,这四大类包含 8 种基本数据类型。
@@ -35,7 +35,7 @@ public static void main(String[] args) {
}
```
-### 包装类型
+## 包装类型
我们知道 8 种基本数据类型都有其对应的包装类,因为 Java 的设计思想是万物既对象,有很多时候我们需要以对象的形式操作某项功能,比如说获取哈希值(hashCode)或获取类(getClass)等。
@@ -121,7 +121,7 @@ public static Integer valueOf(int i) {
- Long:缓存区 -128~127
- Integer:缓存区 -128~127
-### 包装类的注意事项
+## 包装类的注意事项
- int 的默认值是 0,而 Integer 的默认值是 null。
- 推荐所有包装类对象之间的值比较使用 `equals()` 方法,因为包装类的非高频区数据会在堆上产生,而高频区又会复用已有对象,这样会导致同样的代码,因为取值的不同,而产生两种截然不同的结果。代码示例:
@@ -173,9 +173,9 @@ public static void main(String[] args) {
由此可见将 Integer 最大缓存修改为 666 之后,667 不会被缓存,而 -128~666 之间的数都被缓存了。
-### 相关面试题
+## 相关面试题
-#### 1. 以下 Integer 代码输出的结果是?
+### 1. 以下 Integer 代码输出的结果是?
```java
Integer age = 10;
@@ -187,7 +187,7 @@ System.out.println((age == age2) + "," + (age3 == age4));
答:`true,false`
-#### 2. 以下 Double 代码输出的结果是?
+### 2. 以下 Double 代码输出的结果是?
```
Double num = 10d;
@@ -199,7 +199,7 @@ System.out.println((num == num2) + "," + (num3 == num4));
答:`false,false`
-#### 3. 以下程序输出结果是?
+### 3. 以下程序输出结果是?
```java
int i = 100;
@@ -217,7 +217,7 @@ D:false,false
题目分析:有人认为这和 Integer 高速缓存有关系,但你发现把值改为 10000 结果也是 `true,true`,这是因为 Integer 和 int 比较时,会自动拆箱为 int 相当于两个 int 比较,值一定是 `true,true`。
-#### 4. 以下程序执行的结果是?
+### 4. 以下程序执行的结果是?
```java
final int iMax = Integer.MAX_VALUE;
@@ -233,7 +233,7 @@ D:以上都不是
题目解析:这是因为整数在内存中使用的是补码的形式表示,最高位是符号位 0 表示正数,1 表示负数,当执行 +1 时,最高位就变成了 1,结果就成了 -2147483648。
-#### 5. 以下程序执行的结果是?
+### 5. 以下程序执行的结果是?
```java
Set set = new HashSet<>();
@@ -253,36 +253,36 @@ D:以上都不是
题目解析:Short 类型 -1 之后转换成了 Int 类型,remove() 的时候在集合中找不到 Int 类型的数据,所以就没有删除任何元素,执行的结果就是 5。
-#### 6. `short s=2;s=s+1;` 会报错吗?`short s=2;s+=1;` 会报错吗?
+### 6. `short s=2;s=s+1;` 会报错吗?`short s=2;s+=1;` 会报错吗?
答:s=s+1 会报错,s+=1 不会报错,因为 s=s+1 会导致 short 类型升级为 int 类型,所以会报错,而 s+=1 还是原来的 short 类型,所以不会报错。
-#### 7. `float f=3.4;` 会报错吗?为什么?
+### 7. `float f=3.4;` 会报错吗?为什么?
答:会报错,因为值 3.4 是 double 类型,float 类型级别小于 double 类型,所以会报错。如下图所示:

-#### 8. 为什么需要包装类?
+### 8. 为什么需要包装类?
答:需要包装类的原因有两个。
① Java 的设计思想是万物既对象,包装类体现了面向对象的设计理念;
② 包装类包含了很多属性和方法,比基本数据类型功能多,比如提供的获取哈希值(hashCode)或获取类(getClass)的方法等。
-#### 9. 基本类 int 和包装类 Integer,在 -128~127 之间都会复用已有的缓存对象,这种说法正确吗?
+### 9. 基本类 int 和包装类 Integer,在 -128~127 之间都会复用已有的缓存对象,这种说法正确吗?
答:不正确,只有包装类高频区域数据才有缓存。
-#### 10. 包装类 Double 和 Integer 一样都有高频区域数据缓存,这种说法正确吗?
+### 10. 包装类 Double 和 Integer 一样都有高频区域数据缓存,这种说法正确吗?
答:不正确,基本数据类型的包装类只有 Double 和 Float 没有高频区域的缓存。
-#### 11. 包装类的值比较要使用什么方法?
+### 11. 包装类的值比较要使用什么方法?
答:包装类因为有高频区域数据缓存,所以推荐使用 equals() 方法进行值比较。
-#### 12. 包装类有哪些功能?
+### 12. 包装类有哪些功能?
答:包装类提供的功能有以下几个。
@@ -294,11 +294,11 @@ D:以上都不是
详见正文“包装类型”部分内容。
-#### 13. 泛型可以为基本类型吗?为什么?
+### 13. 泛型可以为基本类型吗?为什么?
答:泛型不能使用基本数据类型。泛型在 JVM(Java虚拟机)编译的时候会类型檫除,比如代码 `List list` 在 JVM 编译的时候会转换为 `List list` ,因为泛型是在 JDK 5 时提供的,而 JVM 的类型檫除是为了兼容以前代码的一个折中方案,类型檫除之后就变成了 Object,而 Object 不能存储基本数据类型,但可以使用基本数据类型对应的包装类,所以像 `List list` 这样的代码是不被允许的,编译器阶段会检查报错,而 `List list` 是被允许的。
-#### 14. 选择包装类还是基本类的原则有哪些?
+### 14. 选择包装类还是基本类的原则有哪些?
答:我们知道正确的使用包装类,可以提供程序的执行效率,可以使用已有的缓存,一般情况下选择基本数据类型还是包装类原则有以下几个。
@@ -306,14 +306,14 @@ D:以上都不是
② RPC 方法返回值和参数必须使用包装类;
③ 所有局部变量推荐使用基本数据类型。
-#### 15. 基本数据类型在 JVM 中一定存储在栈中吗?为什么?
+### 15. 基本数据类型在 JVM 中一定存储在栈中吗?为什么?
答:基本数据类型不一定存储在栈中,因为基本类型的存储位置取决于声明的作用域,来看具体的解释。
- 当基本数据类型为局部变量的时候,比如在方法中声明的变量,则存放在方法栈中的,当方法结束系统会释放方法栈,在该方法中的变量也会随着栈的销毁而结束,这也是局部变量只能在方法中使用的原因;
- 当基本数据类型为全局变量的时候,比如类中的声明的变量,则存储在堆上,因为全局变量不会随着某个方法的执行结束而销毁。
-#### 16. 以下程序执行的结果是?
+### 16. 以下程序执行的结果是?
```java
Integer i1 = new Integer(10);
@@ -334,7 +334,7 @@ D:true,false,false
题目解析:new Integer(10) 每次都会创建一个新对象,Integer.valueOf(10) 则会使用缓存池中的对象。
-#### 17. 3*0.1==0.3 返回值是多少?
+### 17. 3*0.1==0.3 返回值是多少?
答:返回值为:false。
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
similarity index 90%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
index 67917a7..7a0e7ad 100644
--- "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
@@ -1,8 +1,8 @@
-## 理解异常处理
+# 理解异常处理
在程序开发中,异常处理也是我们经常使用到的模块,只是平常很少去深究异常模块的一些知识点。比如,try-catch 处理要遵循的原则是什么,finally 为什么总是能执行,try-catch 为什么比较消耗程序的执行性能等问题,我们本讲内容都会给出相应的答案,当然还有面试中经常被问到的异常模块的一些面试题,也是我们本篇要讲解的重点内容。
-### 异常处理基础介绍
+## 异常处理基础介绍
先来看看**异常处理的语法格式**:
@@ -44,7 +44,7 @@ try {

-### 异常处理的发展
+## 异常处理的发展
随着 Java 语言的发展,JDK 7 的时候引入了一些更加便利的特性,用来更方便的处理异常信息,如 try-with-resources 和 multiple catch,具体可以参考下面的代码段:
@@ -57,7 +57,7 @@ try (FileReader fileReader = new FileReader("");
}
```
-### 异常处理的基本原则
+## 异常处理的基本原则
先来看下面这段代码,有没有发现一些问题?
@@ -74,7 +74,7 @@ try {
- 第一,尽量不要捕获通用异常,也就是像 Exception 这样的异常,而是应该捕获特定异常,这样更有助于你发现问题;
- 第二,不要忽略异常,像上面的这段代码只是加了 catch,但没有进行如何的错误处理,信息就已经输出了,这样在程序出现问题的时候,根本找不到问题出现的原因,因此要切记不要直接忽略异常。
-### 异常处理对程序性能的影响
+## 异常处理对程序性能的影响
异常处理固然好用,但一定不要滥用,比如下面的代码片段:
@@ -112,13 +112,13 @@ if (null != jsonStr && !jsonStr.equals("")) {
System.out.println(array.size());
```
-### 相关面试题
+## 相关面试题
-#### 1. try 可以单独使用吗?
+### 1. try 可以单独使用吗?
答:try 不能单独使用,否则就失去了 try 的意义和价值。
-#### 2. 以下 try-catch 可以正常运行吗?
+### 2. 以下 try-catch 可以正常运行吗?
```
try {
@@ -130,7 +130,7 @@ try {
答:不能正常运行,catch 后必须包含异常信息,如 catch (Exception e)。
-#### 3. 以下 try-finally 可以正常运行吗?
+### 3. 以下 try-finally 可以正常运行吗?
```
try {
@@ -142,7 +142,7 @@ try {
答:可以正常运行。
-#### 4. 以下代码 catch 里也发生了异常,程序会怎么执行?
+### 4. 以下代码 catch 里也发生了异常,程序会怎么执行?
```java
try {
@@ -159,7 +159,7 @@ System.out.println("main");
答:程序会打印出 finally 之后抛出异常并终止运行。
-#### 5. 以下代码 finally 里也发生了异常,程序会怎么运行?
+### 5. 以下代码 finally 里也发生了异常,程序会怎么运行?
```
try {
@@ -175,7 +175,7 @@ System.out.println("main");
答:程序在输出 try 之后抛出异常并终止运行,不会再执行 finally 异常之后的代码。
-#### 6. 常见的运行时异常都有哪些?
+### 6. 常见的运行时异常都有哪些?
答:常见的运行时异常如下:
@@ -191,21 +191,21 @@ System.out.println("main");
- java.lang.NoSuchMethodException 方法不存在异常;
- java.lang.IllegalArgumentException 方法传递参数错误。
-#### 7. Exception 和 Error 有什么区别?
+### 7. Exception 和 Error 有什么区别?
答:Exception 和 Error 都属于 Throwable 的子类,在 Java 中只有 Throwable 及其之类才能被捕获或抛出,它们的区别如下:
- Exception(异常)是程序正常运行中,可以预期的意外情况,并且可以使用 try/catch 进行捕获处理的。Exception 又分为运行时异常(Runtime Exception)和受检查的异常(Checked Exception),运行时异常编译能通过,但如果运行过程中出现这类未处理的异常,程序会终止运行;而受检查的异常,要么用 try/catch 捕获,要么用 throws 字句声明抛出,否则编译不会通过。
- Error(错误)是指突发的非正常情况,通常是不可以恢复的,比如 Java 虚拟机内存溢出,诸如此类的问题叫做 Error。
-#### 8. throw 和 throws 的区别是什么?
+### 8. throw 和 throws 的区别是什么?
答:它们的区别如下:
- throw 语句用在方法体内,表示抛出异常由方法体内的语句处理,执行 throw 一定是抛出了某种异常;
- throws 语句用在方法声明的后面,该方法的调用者要对异常进行处理,throws 代表可能会出现某种异常,并不一定会发生这种异常。
-#### 9. Integer.parseInt(null) 和 Double.parseDouble(null) 抛出的异常一样吗?为什么?
+### 9. Integer.parseInt(null) 和 Double.parseDouble(null) 抛出的异常一样吗?为什么?
答:Integer.parseInt(null) 和 Double.parseDouble(null) 抛出的异常类型不一样,如下所示:
@@ -214,17 +214,17 @@ System.out.println("main");
至于为什么会产生不同的异常,其实没有特殊的原因,主要是由于这两个功能是不同人开发的,因而就产生了两种不同的异常信息。
-#### 10. NoClassDefFoundError 和 ClassNoFoundException 有什么区别?
+### 10. NoClassDefFoundError 和 ClassNoFoundException 有什么区别?
- NoClassDefFoundError 是 Error(错误)类型,而 ClassNoFoundExcept 是 Exception(异常)类型;
- ClassNoFoundExcept 是 Java 使用 Class.forName 方法动态加载类,没有加载到,就会抛出 ClassNoFoundExcept 异常;
- NoClassDefFoundError 是 Java 虚拟机或者 ClassLoader 尝试加载类的时候却找不到类订阅导致的,也就是说要查找的类在编译的时候是存在的,运行的时候却找不到,这个时候就会出现 NoClassDefFoundError 的错误。
-#### 11. 使用 try-catch 为什么比较耗费性能?
+### 11. 使用 try-catch 为什么比较耗费性能?
答:这个问题要从 JVM(Java 虚拟机)层面找答案了。首先 Java 虚拟机在构造异常实例的时候需要生成该异常的栈轨迹,这个操作会逐一访问当前线程的栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常等信息,这就是使用异常捕获耗时的主要原因了。
-#### 12. 常见的 OOM 原因有哪些?
+### 12. 常见的 OOM 原因有哪些?
答:常见的 OOM 原因有以下几个:
@@ -232,7 +232,7 @@ System.out.println("main");
- 加载特别大的图片;
- 递归次数过多,并一直操作未释放的变量。
-#### 13. 以下程序的返回结果是?
+### 13. 以下程序的返回结果是?
```java
public static int getNumber() {
@@ -257,13 +257,13 @@ D:1
题目解析:程序最后一定会执行 finally 里的代码,会把之前的结果覆盖为 3。
-#### 14. finally、finalize 的区别是什么?
+### 14. finally、finalize 的区别是什么?
答:finally、finalize 的区别如下:
- finally 是异常处理语句的一部分,表示总是执行;
- finalize 是 Object 类的一个方法,子类可以覆盖该方法以实现资源清理工作,垃圾回收之前会调用此方法。
-#### 15. 为什么 finally 总能被执行?
+### 15. 为什么 finally 总能被执行?
答:finally 总会被执行,都是编译器的作用,因为编译器在编译 Java 代码时,会复制 finally 代码块的内容,然后分别放在 try-catch 代码块所有的正常执行路径及异常执行路径的出口中,这样 finally 才会不管发生什么情况都会执行。
\ No newline at end of file
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\347\261\273\344\270\216Object.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\347\261\273\344\270\216Object.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\347\261\273\344\270\216Object.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\347\261\273\344\270\216Object.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Map.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Map.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Map.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Map.md"
diff --git "a/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\235\242\345\220\221\345\257\271\350\261\241.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\235\242\345\220\221\345\257\271\350\261\241.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md"
index 1926745..36851e0 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,8 +1,4 @@
-
-
-
-
-# ArrayList源码分析
+# 👉 ArrayList源码分析
## 1 底层结构
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index e32c62d..0c646d3 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-## ConcurrentHashMap源码分析
+# 👉 ConcurrentHashMap源码分析
当我们碰到线程不安全场景下,需要使用 Map 的时候,我们第一个想到的 API 估计就是 ConcurrentHashMap,ConcurrentHashMap 内部封装了锁和各种数据结构来保证访问 Map 是线程安全的,接下来我们一一来看下,和 HashMap 相比,多了哪些数据结构,又是如何保证线程安全的。
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index f578794..a648254 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-## HashMap源码分析
+# 👉 HashMap源码分析
## 1 整体架构
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md"
index c83671a..cc56b9d 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-## HashSet与TreeSet
+# 👉 HashSet与TreeSet
HashSet、TreeSet 两个类是在 Map 的基础上组装起来的类,我们学习的侧重点,主要在于 Set 是如何利用 Map 现有的功能,来达成自己的目标的,也就是说如何基于现有的功能进行创新,然后再看看一些改变的小细节是否值得我们学习。
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index ecd3e53..897ddbb 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-# LinkedHashMap源码分析
+# 👉 LinkedHashMap源码分析
HashMap 是无序的,TreeMap 可以按照 key 进行排序,那有木有 Map 是可以维护插入的顺序的呢?接下来我们一起来看下 LinkedHashMap。
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/README.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/README.md"
new file mode 100644
index 0000000..a788b3f
--- /dev/null
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/README.md"
@@ -0,0 +1,8 @@
+# Java并发编程
+
+* [ArrayList源码分析](docs/Java源码分析/ArrayList源码分析.md)
+* [HashMap源码分析](docs/Java源码分析/HashMap源码分析.md)
+* [HashSet与TreeSet源码分析](docs/Java源码分析/HashSet与TreeSet源码分析.md)
+* [LinkedHashMap源码分析](docs/Java源码分析/LinkedHashMap源码分析.md)
+* [TreeMap源码分析](docs/Java源码分析/TreeMap源码分析.md)
+
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index 58715aa..5db0820 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-# TreeMap源码分析
+# 👉 TreeMap源码分析
## 1 知识储备
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/_sidebar.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/_sidebar.md"
new file mode 100644
index 0000000..bf4f932
--- /dev/null
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/_sidebar.md"
@@ -0,0 +1,6 @@
+* **👉 Java源码分析** [↩](/README)
+ * [ArrayList源码分析](docs/Java源码分析/ArrayList源码分析.md)
+ * [HashMap源码分析](docs/Java源码分析/HashMap源码分析.md)
+ * [HashSet与TreeSet源码分析](docs/Java源码分析/HashSet与TreeSet源码分析.md)
+ * [LinkedHashMap源码分析](docs/Java源码分析/LinkedHashMap源码分析.md)
+ * [TreeMap源码分析](docs/Java源码分析/TreeMap源码分析.md)
\ No newline at end of file
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md"
new file mode 100644
index 0000000..596b465
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md"
@@ -0,0 +1,110 @@
+# 👉 JVM确认可回收对象的方式
+
+## 前言
+
+在开始之前,我们先回顾一下`堆`是个什么玩意,大家可能都知道,我们每天创建的Java对象几乎都存放在堆上面,所以说堆是一个巨大的对象池一点都不过分,在这个对象池里面管理者数据巨大的对象实例。
+
+在对象池中对象的引用层次,有的是很深的。比如一个调用非常频繁的接口,生产对象的速度是非常可观的。对象之间的关系,可以形容成一张网。虽然Java总是给人一种有使不完的内存的感觉,但是对象也不能一直增加不减少啊,所以就必须有**垃圾回收**这个操作。
+
+## JVM是怎么认识`垃圾`的呢?
+
+**"垃圾回收"本文中简称 GC**
+
+你还记得电视剧中的“诛九族""?
+
+
-
-+ 程序计数器
-
-程序计数器是一块很小的内存空间,用于存储当前运行的线程所执行的字节码的行号指令,每个运行中的线程都有一个独立的程序计数器,在方法正在执行时,该方法的程序计数器记录的是实时虚拟机字节码指令的地址;如果该方法执行的是Native方法,则程序计数器的值为空。
-
-+ 虚拟机栈
-
-虚拟机栈是描述Java方法的执行过程的内存模型,它在当前栈帧存储了局部变量表、操作数栈、动态链接、方法出口等信息。同时,栈帧用来存储部分运行时数据及其数据结构,处理动态链接方法的返回值和异常分派。
-
-+ 本地方法区
-
-本地方法区和虚拟机栈作用类似,区别就是本地方法栈是为Native方法服务,而虚拟机栈是为了Java方法服务。
-
-+ 堆内存
-
-在JVM运行过程中创建的对象和产生的数据都被存储在堆中,堆是被线程共享的内存区域,也是垃圾收集器进行垃圾回首的最主要的内存区域。
-
-+ 方法区
-
-方法区用于存储常量、静态变量、类信息、即时编译器编译后的机器码、运行时常量等数据。
-
-
-
diff --git "a/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/README.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/README.md"
new file mode 100644
index 0000000..94e0a88
--- /dev/null
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/README.md"
@@ -0,0 +1,17 @@
+# Java并发编程
+ * [为什么说本质上实现线程的方法只有一种](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
+ * [可能会遇到的三类线程安全问题](docs/Java并发编程/可能会遇到的三类线程安全问题.md)
+ * [哪些场景需要额外注意线程安全问题](docs/Java并发编程/哪些场景需要额外注意线程安全问题.md)
+ * [理解Callable和Runnable的不同](docs/Java并发编程/理解Callable和Runnable的不同.md)
+ * [理解CAS优缺点](docs/Java并发编程/理解CAS优缺点.md)
+ * [理解Java中的各种锁](docs/Java并发编程/理解Java中的各种锁.md)
+ * [理解Java中的锁及其特点](docs/Java并发编程/理解Java中的锁及其特点.md)
+ * [理解JVM内存结构与Java内存模型](docs/Java并发编程/理解JVM内存结构与Java内存模型.md)
+ * [理解synchronized关键字](docs/Java并发编程/理解synchronized关键字.md)
+ * [理解ThreadLocal](docs/Java并发编程/理解ThreadLocal.md)
+ * [理解线程与死锁](docs/Java并发编程/理解线程与死锁.md)
+ * [理解线程安全synchronized与ReentrantLock](docs/Java并发编程/理解线程安全synchronized与ReentrantLock.md)
+ * [理解线程池](docs/Java并发编程/理解线程池.md)
+ * [理解线程池4种拒绝策略](docs/Java并发编程/理解线程池4种拒绝策略.md)
+ * [理解线程的状态及如何进行转换的](docs/Java并发编程/理解线程的状态及如何进行转换的.md)
+ * [第2章Java并发机制的底层原理](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
diff --git "a/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/_sidebar.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/_sidebar.md"
new file mode 100644
index 0000000..5b75b0c
--- /dev/null
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/_sidebar.md"
@@ -0,0 +1,17 @@
+* **👉 Java并发编程** [↩](/README)
+ * [为什么说本质上实现线程的方法只有一种](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
+ * [可能会遇到的三类线程安全问题](docs/Java并发编程/可能会遇到的三类线程安全问题.md)
+ * [哪些场景需要额外注意线程安全问题](docs/Java并发编程/哪些场景需要额外注意线程安全问题.md)
+ * [理解Callable和Runnable的不同](docs/Java并发编程/理解Callable和Runnable的不同.md)
+ * [理解CAS优缺点](docs/Java并发编程/理解CAS优缺点.md)
+ * [理解Java中的各种锁](docs/Java并发编程/理解Java中的各种锁.md)
+ * [理解Java中的锁及其特点](docs/Java并发编程/理解Java中的锁及其特点.md)
+ * [理解JVM内存结构与Java内存模型](docs/Java并发编程/理解JVM内存结构与Java内存模型.md)
+ * [理解synchronized关键字](docs/Java并发编程/理解synchronized关键字.md)
+ * [理解ThreadLocal](docs/Java并发编程/理解ThreadLocal.md)
+ * [理解线程与死锁](docs/Java并发编程/理解线程与死锁.md)
+ * [理解线程安全synchronized与ReentrantLock](docs/Java并发编程/理解线程安全synchronized与ReentrantLock.md)
+ * [理解线程池](docs/Java并发编程/理解线程池.md)
+ * [理解线程池4种拒绝策略](docs/Java并发编程/理解线程池4种拒绝策略.md)
+ * [理解线程的状态及如何进行转换的](docs/Java并发编程/理解线程的状态及如何进行转换的.md)
+ * [第2章Java并发机制的底层原理](docs/Java并发编程/为什么说本质上实现线程的方法只有一种.md)
\ No newline at end of file
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
index 06f4100..aaa6efc 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\344\270\272\344\273\200\344\271\210\350\257\264\346\234\254\350\264\250\344\270\212\345\256\236\347\216\260\347\272\277\347\250\213\347\232\204\346\226\271\346\263\225\345\217\252\346\234\211\344\270\200\347\247\215.md"
@@ -1,4 +1,4 @@
-# 为什么说本质上实现线程的方法只有一种?
+# 👉 为什么说本质上实现线程的方法只有一种?
> 在本课时我们主要学习为什么说本质上只有一种实现线程的方式?实现 Runnable 接口究竟比继承 Thread 类实现线程好在哪里?
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
index 65e0584..7a27b33 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\217\257\350\203\275\344\274\232\351\201\207\345\210\260\347\232\204\344\270\211\347\261\273\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
@@ -1,3 +1,5 @@
+# 👉 可能会遇到的三类线程安全问题
+
>本文我们一起学习在实际工作中可能会遇到的三类线程安全问题。
## 什么是线程安全
要想弄清楚有哪 3 类线程安全问题,首先需要了解什么是线程安全,线程安全经常在工作中被提到,比如:你的对象不是线程安全的,你的线程发生了安全错误,虽然线程安全经常被提到,但我们可能对线程安全并没有一个明确的定义。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
index 25ee63f..a30ac4f 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\345\223\252\344\272\233\345\234\272\346\231\257\351\234\200\350\246\201\351\242\235\345\244\226\346\263\250\346\204\217\347\272\277\347\250\213\345\256\211\345\205\250\351\227\256\351\242\230.md"
@@ -1,7 +1,6 @@
-> 本文我们一起学习在实际开发中哪些场景需要额外注意线程安全问题?
-
-
+# 👉 哪些场景需要额外注意线程安全问题
+> 本文我们一起学习在实际开发中哪些场景需要额外注意线程安全问题?
## 1.访问共享变量或资源
第一种场景是访问共享变量或共享资源的时候,典型的场景有访问共享对象的属性,访问 static 静态变量,访问共享的缓存,等等。因为这些信息不仅会被一个线程访问到,还有可能被多个线程同时访问,那么就有可能在并发读写的情况下发生线程安全问题。比如我们上一课时讲过的多线程同时 i++ 的例子:
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
index 62d4d91..1c3a819 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243CAS\344\274\230\347\274\272\347\202\271.md"
@@ -1,4 +1,4 @@
-# CAS有很多优点,但它的缺点呢?
+# 👉 CAS有很多优点,但它的缺点呢?
> 本文我们一起学习探讨CAS的缺点。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
index 33bc68b..5d0f976 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Callable\345\222\214Runnable\347\232\204\344\270\215\345\220\214.md"
@@ -1,5 +1,5 @@
-# Callable和Runnable的不同?
+# 👉 Callable和Runnable的不同?
> 本文我们一起学习 Callable 和 Runnable 的不同。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
similarity index 97%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
index d9c5bd5..7c8fcff 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243JVM\345\206\205\345\255\230\347\273\223\346\236\204\344\270\216Java\345\206\205\345\255\230\346\250\241\345\236\213.md"
@@ -1,5 +1,4 @@
-
-# 不要在混淆JVM内存结构与Java内存模型了!
+# 👉 不要在混淆JVM内存结构与Java内存模型了!
> 本文我们一起学习什么是Java内存模型。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
index 03a4f68..2a28a65 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
@@ -1,4 +1,4 @@
-## 理解Java中的各种锁
+# 👉 理解Java中的各种锁
如果说快速理解多线程有什么捷径的话,那本文介绍的各种锁无疑是其中之一,它不但为我们开发多线程程序提供理论支持,还是面试中经常被问到的核心面试题之一。因此下面就让我们一起深入地学习一下这些锁吧。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
index 0adcda7..657c578 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243Java\344\270\255\347\232\204\351\224\201\345\217\212\345\205\266\347\211\271\347\202\271.md"
@@ -1,4 +1,4 @@
-# Java中哪几种锁?分别有什么特点?
+# 👉 Java中哪几种锁?分别有什么特点?
> 本文中我们一起学习Java中锁的分类及其特点。
锁是用来控制多线程访问共享资源的方式,一般的讲,一个锁能够防止多个线程同时访问共享资源。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
index b78f9b6..fc69799 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243ThreadLocal.md"
@@ -1,4 +1,4 @@
-## 理解ThreadLocal
+# 👉 理解ThreadLocal
**什么是 ThreadLocal?**
ThreadLocal 诞生于 JDK 1.2,用于解决多线程间的数据隔离问题。也就是说 ThreadLocal 会为每一个线程创建一个单独的变量副本。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
index 779eda2..8b0626b 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243synchronized\345\205\263\351\224\256\345\255\227.md"
@@ -1,4 +1,4 @@
-# synchronized关键字原理
+# 👉 synchronized关键字原理
众所周知 `synchronized` 关键字是解决并发问题常用解决方案,有以下三种使用方式:
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
index 8637caa..68ce72c 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\344\270\216\346\255\273\351\224\201.md"
@@ -1,4 +1,4 @@
-## 理解线程与死锁
+# 👉 理解线程与死锁
### 线程介绍
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
similarity index 99%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
index 393737a..92af496 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\345\256\211\345\205\250synchronized\344\270\216ReentrantLock.md"
@@ -1,4 +1,4 @@
-## 理解线程安全synchronized与ReentrantLock
+# 👉 理解线程安全synchronized与ReentrantLock
前面我们介绍了很多关于多线程的内容,在多线程中有一个很重要的课题需要我们攻克,那就是线程安全问题。线程安全问题指的是在多线程中,各线程之间因为同时操作所产生的数据污染或其他非预期的程序运行结果。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md"
similarity index 100%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\240.md"
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
index c9a9297..90500ee 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\346\261\2404\347\247\215\346\213\222\347\273\235\347\255\226\347\225\245.md"
@@ -1,10 +1,9 @@
-> 本文我们一起学习线程池有哪 4 种默认的拒绝策略。
+# 👉 线程池的拒绝策略
-# 线程池的拒绝策略
+> 本文我们一起学习线程池有哪 4 种默认的拒绝策略。
若线程池中的核心线程数被用完且阻塞队列已排满,则此时线程池的资源已耗尽,线程池将没有足够的线程资源执行新的任务。为了保证操作系统的安全,线程池将通过拒绝策略处理新添加的线程任务。
-
## 1. AbortPolicy
第一种拒绝策略是 `AbortPolicy`,这种拒绝策略在拒绝任务时,会直接抛出一个类型为 RejectedExecutionException的RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
diff --git "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
similarity index 98%
rename from "docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
index 3618b62..1612d62 100644
--- "a/docs/\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
+++ "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\220\206\350\247\243\347\272\277\347\250\213\347\232\204\347\212\266\346\200\201\345\217\212\345\246\202\344\275\225\350\277\233\350\241\214\350\275\254\346\215\242\347\232\204.md"
@@ -1,3 +1,4 @@
+# 👉 理解线程的状态及如何进行转换的
> 本文我们一起学习线程的状态有哪些以及它们之间是如何进行转换的?
线程(Thread)是并发编程的基础,也是程序执行的最小单元,它依托进程而存在。一个进程中可以包含多个线程,多线程可以共享一块内存空间和一组系统资源,因此线程之间的切换更加节省资源、更加轻量化,也因此被称为轻量级的进程。
diff --git "a/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md" "b/docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md"
similarity index 100%
rename from "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md"
rename to "docs/Java\345\271\266\345\217\221\347\274\226\347\250\213/\347\254\2542\347\253\240Java\345\271\266\345\217\221\346\234\272\345\210\266\347\232\204\345\272\225\345\261\202\345\216\237\347\220\206.md"
diff --git "a/docs/Java\345\274\200\345\217\221\350\247\204\350\214\203/Java\345\274\200\345\217\221\346\211\213\345\206\214\345\265\251\345\261\261\347\211\210.md" "b/docs/Java\345\274\200\345\217\221\350\247\204\350\214\203/Java\345\274\200\345\217\221\346\211\213\345\206\214\345\265\251\345\261\261\347\211\210.md"
new file mode 100644
index 0000000..f67b914
--- /dev/null
+++ "b/docs/Java\345\274\200\345\217\221\350\247\204\350\214\203/Java\345\274\200\345\217\221\346\211\213\345\206\214\345\265\251\345\261\261\347\211\210.md"
@@ -0,0 +1,255 @@
+# 👉 Java开发手册 嵩山版
+
+| 版本 | 制定 | 更新日期 | 备注 |
+| :---: | :----------------------------: | :--------: | :------------------------: |
+| 1.7.0 | 阿里巴巴与全球 Java 社区开发者 | 2020.08.03 | 嵩山版,首次发布前后端规约
+
+ ## 一、 编程规约
+
+### (一) 命名风格
+
+1. **【强制】代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。**
+
+ > **反例:_name / __name / $name / name_ / name$ / name__**
+
+2. **【强制】所有编程相关的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。**
+
+ **说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。注意,纯拼音命名方式更要避免采用。**
+
+ > **正例:ali / alibaba / taobao / cainiao/ aliyun/ youku / hangzhou 等国际通用的名称,可视同英文。**
+ >
+ > **反例:DaZhePromotion [打折] / getPingfenByName() [评分] / String fw[福娃] / int 某变量 = 3**
+
+3. **【强制】代码和注释中都要避免使用任何语言的种族歧视性词语。**
+
+ > **正例:日本人 / 印度人 / blockList / allowList / secondary**
+ >
+ > **反例:RIBENGUIZI / Asan / blackList / whiteList / slave**
+
+4. **【强制】类名使用 UpperCamelCase 风格,但以下情形例外:DO / BO / DTO / VO / AO / PO / UID 等。**
+
+ > **正例:ForceCode / UserDO / HtmlDTO / XmlService / TcpUdpDeal / TaPromotion**
+ >
+ > **反例:forcecode / UserDo / HTMLDto / XMLService / TCPUDPDeal / TAPromotion**
+
+5. **【强制】方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格。**
+
+ > **正例: localValue / getHttpMessage() / inputUserId**
+
+6. **【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。**
+
+ > **正例:MAX_STOCK_COUNT / CACHE_EXPIRED_TIME 反例:MAX_COUNT / EXPIRED_TIME**
+
+7. **【强制】抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类 命名以它要测试的类的名称开始,以 Test 结尾。**
+
+8. **【强制】类型与中括号紧挨相连来表示数组。 正例:定义整形数组 int[] arrayDemo。**
+
+ > **反例:在 main 参数中,使用 String args[]来定义。**
+
+9. **【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列 化错误。**
+
+ **说明:在本文 MySQL 规约中的建表约定第一条,表达是与否的变量采用 is_xxx 的命名方式,所以,需要 在设置从 is_xxx 到 xxx 的映射关系。**
+
+ > **反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时 候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。**
+
+10. **【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用 单数形式,但是类名如果有复数含义,类名可以使用复数形式。**
+
+ > **正例:应用工具类包名为 com.alibaba.ei.kunlun.aap.util、类名为 MessageUtils(此规则参考 spring 的 框架结构)**
+
+11. **【强制】避免在子父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名, 使可理解性降低。**
+
+ **说明:子类、父类成员变量名相同,即使是 public 类型的变量也能够通过编译,另外,局部变量在同一方 法内的不同代码块中同名也是合法的,这些情况都要避免。对于非 setter/getter 的参数名称也要避免与成 员变量名称相同。**
+
+ ```java
+ 反例:
+ public class ConfusingName {
+ public int stock;
+ // 非 setter/getter 的参数名称,不允许与本类成员变量同名
+ public void get(String alibaba) {
+ if (condition) {
+ final int money = 666;
+ // ...
+ }
+ for (int i = 0; i < 10; i++) {
+ // 在同一方法体中,不允许与其它代码块中的 money 命名相同
+ final int money = 15978;
+ // ...
+ }
+ }
+ }
+ class Son extends ConfusingName {
+ // 不允许与父类的成员变量名称相同
+ public int stock;
+ }
+ ```
+
+12. **【强制】杜绝完全不规范的缩写,避免望文不知义。**
+
+ > **反例:AbstractClass“缩写”成 AbsClass;condition“缩写”成 condi;Function 缩写”成 Fu,此类 随意缩写严重降低了代码的可阅读性。**
+
+13. **【推荐】为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组 合来表达。**
+
+ > **正例:对某个对象引用的 volatile 字段进行原子更新的类名为 AtomicReferenceFieldUpdater。**
+ >
+ > **反例:常见的方法内变量为 int a;的定义方式**。
+
+14. **【推荐】在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。**
+
+ > **正例:startTime / workQueue / nameList / TERMINATED_THREAD_COUNT**
+ >
+ > **反例:startedAt / QueueOfWork / listName / COUNT_TERMINATED_THREAD**
+
+15. **【推荐】如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式。**
+
+ **说明:将设计模式体现在名字中,有利于阅读者快速理解架构设计理念。**
+
+ > 正例: public class OrderFactory;
+ >
+ > public class LoginProxy;
+ >
+ > public class ResourceObserver;
+
+16. **【推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁 性,并加上有效的 Javadoc 注释。尽量不要在接口里定义变量,如果一定要定义变量,确定 与接口方法相关,并且是整个应用的基础常量。**
+
+ > 正例:接口方法签名 void commit(); 接口基础常量 String COMPANY = "alibaba";
+ >
+ > 反例:接口方法定义 public abstract void f();
+
+ **说明:JDK8 中接口允许有默认实现,那么这个 default 方法,是对所有实现类都有价值的默认实现。**
+
+17. **接口和实现类的命名有两套规则:**
+
+ **1)【强制】对于 Service 和 DAO 类,基于 SOA 的理念,暴露出来的服务一定是接口,内部的实现类用 Impl 的后缀与接口区别。**
+
+ > **正例:CacheServiceImpl 实现 CacheService 接口。**
+
+ **2)【推荐】如果是形容能力的接口名称,取对应的形容词为接口名(通常是–able 的形容词)。**
+
+ > **正例:AbstractTranslator 实现 Translatable 接口。**
+
+18. **【参考】枚举类名带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。**
+
+ **说明:枚举其实就是特殊的常量类,且构造方法被默认强制是私有。**
+
+ > 正例:枚举名字为 ProcessStatusEnum 的成员名称:SUCCESS / UNKNOWN_REASON。
+
+19. **【参考】各层命名规约:**
+
+ **A) Service/DAO 层方法命名规约**
+
+ **1) 获取单个对象的方法用 get 做前缀。**
+
+ **2) 获取多个对象的方法用 list 做前缀,复数结尾,如:listObjects。**
+
+ **3) 获取统计值的方法用 count 做前缀。**
+
+ **4) 插入的方法用 save/insert 做前缀。**
+
+ **5) 删除的方法用 remove/delete 做前缀。**
+
+ **6) 修改的方法用 update 做前缀。**
+
+ **B) 领域模型命名规约 Java 开发手册 4/59**
+
+ **1) 数据对象:xxxDO,xxx 即为数据表名。**
+
+ **2) 数据传输对象:xxxDTO,xxx 为业务领域相关的名称。**
+
+ **3) 展示对象:xxxVO,xxx 一般为网页名称。**
+
+ **4) POJO 是 DO/DTO/BO/VO 的统称,禁止命名成 xxxPOJO。**
+
+### (二) 常量定义
+
+1. **【强制】不允许任何魔法值(即未经预先定义的常量)直接出现在代码中。**
+
+ > **反例: // 本例中,开发者 A 定义了缓存的 key,然后开发者 B 使用缓存时少了下划线,即 key 是"Id#taobao"+tradeId,导致 出现故障**
+ >
+ > **String key = "Id#taobao_" + tradeId; cache.put(key, value);**
+
+2. **【强制】在 long 或者 Long 赋值时,数值后使用大写字母 L,不能是小写字母 l,小写容易跟 数字混淆,造成误解。**
+
+ > **说明:Long a = 2l; 写的是数字的 21,还是 Long 型的 2?**
+
+3. 【**推荐】不要使用一个常量类维护所有常量,要按常量功能进行归类,分开维护。**
+
+ **说明:大而全的常量类,杂乱无章,使用查找功能才能定位到修改的常量,不利于理解,也不利于维护。**
+
+ > **正例:缓存相关常量放在类 CacheConsts 下;系统配置相关常量放在类 SystemConfigConsts 下。**
+
+4. **【推荐】常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包 内共享常量、类内共享常量。**
+
+ **1) 跨应用共享常量:放置在二方库中,通常是 client.jar 中的 constant 目录下。**
+
+ **2) 应用内共享常量:放置在一方库中,通常是子模块中的 constant 目录下。**
+
+ > **反例:易懂变量也要统一定义成应用内共享常量,两位工程师在两个类中分别定义了“YES”的变量:**
+ >
+ > **类 A 中:public static final String YES = "yes";**
+ >
+ > **类 B 中:public static final String YES = "y"; A.YES.equals(B.YES),预期是 true,但实际返回为 false,导致线上问题。**
+
+ **3) 子工程内部共享常量:即在当前子工程的 constant 目录下。**
+
+ **4) 包内共享常量:即在当前包下单独的 constant 目录下。**
+
+ **5) 类内共享常量:直接在类内部 private static final 定义。**
+
+5.
+
+### (三) 代码格式
+
+### (四) OOP 规约
+
+### (五) 日期时间
+
+### (六) 集合处理
+
+### (七) 并发处理
+
+### (八) 控制语句
+
+### (九) 注释规约
+
+### (十) 前后端规约
+
+### (十一) 其他
+
+## 二、异常日志
+
+### (一) 错误码
+
+### (二) 异常处理
+
+### (三) 日志规约
+
+## 三、单元测试
+
+## 四、安全规约
+
+## 五、MySQL 数据库
+
+### (一) 建表规约
+
+### (二) 索引规约
+
+### (三) SQL 语句
+
+### (四) ORM 映射
+
+## 六、工程结构
+
+### (一) 应用分层
+
+### (二) 二方库依赖
+
+### (三) 服务器
+
+## 七、设计规约
+
+# 附 1:专有名词解释
+
+# 附 2:错误码列表
+
+
+
diff --git "a/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/README.md" "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/README.md"
new file mode 100644
index 0000000..47f4eec
--- /dev/null
+++ "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/README.md"
@@ -0,0 +1,3 @@
+# Java性能优化
+
+* [常见Java代码优化法则](docs/Java并发编程/常见Java代码优化法则.md)
diff --git "a/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/_sidebar.md" "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/_sidebar.md"
new file mode 100644
index 0000000..828be2b
--- /dev/null
+++ "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/_sidebar.md"
@@ -0,0 +1,3 @@
+* **👉 Java性能优化** [↩](/README)
+ * [常见Java代码优化法则](docs/Java性能优化/常见Java代码优化法则.md)
+
\ No newline at end of file
diff --git "a/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/\345\270\270\350\247\201Java\344\273\243\347\240\201\344\274\230\345\214\226\346\263\225\345\210\231.md" "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/\345\270\270\350\247\201Java\344\273\243\347\240\201\344\274\230\345\214\226\346\263\225\345\210\231.md"
new file mode 100644
index 0000000..2eb7417
--- /dev/null
+++ "b/docs/Java\346\200\247\350\203\275\344\274\230\345\214\226/\345\270\270\350\247\201Java\344\273\243\347\240\201\344\274\230\345\214\226\346\263\225\345\210\231.md"
@@ -0,0 +1,89 @@
+# 👉 常见Java代码优化法则
+
+## 1.使用局部变量可避免在堆上分配
+由于堆资源是多线程共享的,是垃圾回收器工作的主要区域,过多的对象会造成 GC 压力。可以通过局部变量的方式,将变量在栈上分配。这种方式变量会随着方法执行的完毕而销毁,能够减轻 GC 的压力。
+
+## 2.削弱变量的作用范围
+注意变量的作用范围,尽量减少对象的创建。如下面的代码,变量 a 每次进入方法都会创建,可以将它移动到 if 语句内部。
+
+## 3.使用类名方式访问静态变量
+有的同学习惯使用对象访问静态变量,这种方式多了一步寻址操作,需要先找到变量对应的类,再找到类对应的变量。
+
+## 4.字符串拼接不要使用 ”+”
+字符串拼接,使用 `StringBuilder `或者` StringBuffer`,不要使用 + 号。
+
+## 5.重写对象的`HashCode`,不要简单地返回固定值
+开发时重写 `HashCode` 和`Equals` 方法时,会把 `HashCode `的值返回固定的 0,而这样做是不恰当的。
+
+当这些对象存入 `HashMap` 时,性能就会非常低,因为 `HashMap `是通过 `HashCode` 定位到 Hash 槽,有冲突的时候,才会使用链表或者红黑树组织节点。固定地返回 0,相当于把 Hash 寻址功能给废除了。
+
+## 6.`HashMap `等集合初始化的时候,尽量指定初始值大小
+通过指定初始值大小可减少扩容造成的性能损耗。
+
+## 7.遍历`Map` 的时候,使用 `EntrySet` 方法
+使用 EntrySet 方法,可以直接返回 set 对象,直接拿来用即可;而使用 KeySet 方法,获得的是key 的集合,需要再进行一次 get 操作,多了一个操作步骤。所以更推荐使用 EntrySet 方式遍历 Map。
+
+## 8.不要在多线程下使用同一个 Random
+Random 类的 seed 会在并发访问的情况下发生竞争,造成性能降低,建议在多线程环境下使用 `ThreadLocalRandom` 类。
+
+> 在 Linux 上,通过加入 JVM 配置 -Djava.security.egd=file:/dev/./urandom,使用 urandom 随机生成器,在进行随机数获取时,速度会更快。
+
+## 9.自增推荐使用 LongAddr
+自增运算可以通过 synchronized 和 volatile 的组合,或者也可以使用原子类(比如 AtomicLong)。
+
+后者的速度比前者要高一些,AtomicLong 使用 CAS 进行比较替换,在线程多的情况下会造成过多无效自旋,所以可以使用 LongAdder 替换 AtomicLong 进行进一步的性能提升。
+
+## 10.不要使用异常控制程序流程
+异常,是用来了解并解决程序中遇到的各种不正常的情况,它的实现方式比较昂贵,比平常的条件判断语句效率要低很多。
+
+这是因为异常在字节码层面,需要生成一个如下所示的异常表(Exception table),多了很多判断步骤。
+
+## 11.不要在循环中使用 try catch
+道理与上面类似,很多文章介绍,不要把异常处理放在循环里,而应该把它放在最外层,但实际测试情况表明这两种方式性能相差并不大。
+
+既然性能没什么差别,那么就推荐根据业务的需求进行编码。比如,循环遇到异常时,不允许中断,也就是允许在发生异常的时候能够继续运行下去,那么异常就只能在 for 循环里进行处理。
+
+## 12.不要捕捉 RuntimeException
+Java 异常分为两种,一种是可以通过预检查机制避免的 RuntimeException;另外一种就是普通异常。
+
+其中,RuntimeException 不应该通过 catch 语句去捕捉,而应该使用编码手段进行规避。
+
+## 13.合理使用 PreparedStatement
+PreparedStatement 使用预编译对 SQL 的执行进行提速,大多数数据库都会努力对这些能够复用的查询语句进行预编译优化,并能够将这些编译结果缓存起来。
+
+这样等到下次用到的时候,就可以很快进行执行,也就少了一步对 SQL 的解析动作。
+
+PreparedStatement 还能提高程序的安全性,能够有效防止 SQL 注入。
+
+但如果你的程序每次 SQL 都会变化,不得不手工拼接一些数据,那么 PreparedStatement 就失去了它的作用,反而使用普通的 Statement 速度会更快一些。
+
+## 14.日志打印的注意事项
+ debug 输出一些调试信息,然后在线上关掉它。
+
+## 15.减少事务的作用范围
+如果的程序使用了事务,那一定要注意事务的作用范围,尽量以最快的速度完成事务操作。这是因为,事务的隔离性是使用锁实现的。
+
+## 16.使用位移操作替代乘除法
+计算机是使用二进制表示的,位移操作会极大地提高性能。
+
+- `<<` 左移相当于乘以 2;
+- `<<` 右移相当于除以 2;
+- `>>>`无符号右移相当于除以 2,但它会忽略符号位,空位都以 0 补齐。
+
+## 17.不要打印大集合或者使用大集合的 toString 方法
+有的开发喜欢将集合作为字符串输出到日志文件中,这个习惯是非常不好的。
+
+拿 ArrayList 来说,它需要遍历所有的元素来迭代生成字符串。在集合中元素非常多的情况下,这不仅会占用大量的内存空间,执行效率也非常慢
+
+## 18.尽量少在程序中使用反射
+反射的功能很强大,但它是通过解析字节码实现的,性能就不是很理想。
+
+现实中有很多对反射的优化方法,比如把反射执行的过程(比如 Method)缓存起来,使用复用来加快反射速度。
+
+Java 7.0 之后,加入了新的包 java.lang.invoke,同时加入了新的 JVM 字节码指令 invokedynamic,用来支持从 JVM 层面,直接通过字符串对目标方法进行调用。
+
+如果你对性能有非常苛刻的要求,则使用 invoke 包下的 MethodHandle 对代码进行着重优化,但它的编程不如反射方便,在平常的编码中,反射依然是首选。
+
+## 19.正则表达式可以预先编译,加快速度
+Java 的正则表达式需要先编译再使用。
+
diff --git "a/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/README.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/README.md"
new file mode 100644
index 0000000..a816816
--- /dev/null
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/README.md"
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git "a/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/_sidebar.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/_sidebar.md"
new file mode 100644
index 0000000..fae09b2
--- /dev/null
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/_sidebar.md"
@@ -0,0 +1,20 @@
+* **👉 Java核心基础** [↩](/README)
+ * [理解Java关键字](docs/Java核心基础/理解Java关键字.md)
+ * [理解String字符串](docs/Java核心基础/理解String字符串.md)
+ * [理解基本数据类型与包装类](docs/Java核心基础/理解基本数据类型与包装类.md)
+ * [理解各种内部类和枚举类](docs/Java核心基础/理解各种内部类和枚举类.md)
+ * [理解动态代理](docs/Java核心基础/理解动态代理.md)
+ * [理解克隆与序列化应用](docs/Java核心基础/理解克隆与序列化应用.md)
+ * [理解异常处理](docs/Java核心基础/理解异常处理.md)
+ * [理解抽象类与接口](docs/Java核心基础/理解抽象类与接口.md)
+ * [理解泛型与迭代器](docs/Java核心基础/理解泛型与迭代器.md)
+ * [理解浅克隆和深克隆](docs/Java核心基础/理解浅克隆和深克隆.md)
+ * [理解类与Object](docs/Java核心基础/理解类与Object.md)
+ * [理解集合Collection](docs/Java核心基础/理解集合Collection.md)
+ * [理解集合Map](docs/Java核心基础/理解集合Map.md)
+ * [理解Java中的各种锁](docs/Java核心基础/理解Java中的各种锁.md)
+ * [理解HashMap底层实现原理](docs/Java核心基础/理解HashMap底层实现原理.md)
+ * [理解HashMap为什么是线程不安全的](docs/Java核心基础/理解HashMap为什么是线程不安全的.md)
+ * [理解ConcurrentHashMap底层实现原理](docs/Java核心基础/理解ConcurrentHashMap底层实现原理.md)
+ * [理解数据结构队列](docs/Java核心基础/理解数据结构队列.md)
+
\ No newline at end of file
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243ConcurrentHashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\344\270\272\344\273\200\344\271\210\346\230\257\347\272\277\347\250\213\344\270\215\345\256\211\345\205\250\347\232\204.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243HashMap\345\272\225\345\261\202\345\256\236\347\216\260\345\216\237\347\220\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\344\270\255\347\232\204\345\220\204\347\247\215\351\224\201.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243Java\345\205\263\351\224\256\345\255\227.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243String\345\255\227\347\254\246\344\270\262.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\205\213\351\232\206\344\270\216\345\272\217\345\210\227\345\214\226\345\272\224\347\224\250.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\212\250\346\200\201\344\273\243\347\220\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\220\204\347\247\215\345\206\205\351\203\250\347\261\273\345\222\214\346\236\232\344\270\276\347\261\273.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
similarity index 91%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
index 659c6f0..6ca3096 100644
--- "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\237\272\346\234\254\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\214\205\350\243\205\347\261\273.md"
@@ -1,6 +1,6 @@
-## 理解基本数据类型与包装类
+# 理解基本数据类型与包装类
-### 基本数据类型
+## 基本数据类型
Java 基本数据按类型可以分为四大类:布尔型、整数型、浮点型、字符型,这四大类包含 8 种基本数据类型。
@@ -35,7 +35,7 @@ public static void main(String[] args) {
}
```
-### 包装类型
+## 包装类型
我们知道 8 种基本数据类型都有其对应的包装类,因为 Java 的设计思想是万物既对象,有很多时候我们需要以对象的形式操作某项功能,比如说获取哈希值(hashCode)或获取类(getClass)等。
@@ -121,7 +121,7 @@ public static Integer valueOf(int i) {
- Long:缓存区 -128~127
- Integer:缓存区 -128~127
-### 包装类的注意事项
+## 包装类的注意事项
- int 的默认值是 0,而 Integer 的默认值是 null。
- 推荐所有包装类对象之间的值比较使用 `equals()` 方法,因为包装类的非高频区数据会在堆上产生,而高频区又会复用已有对象,这样会导致同样的代码,因为取值的不同,而产生两种截然不同的结果。代码示例:
@@ -173,9 +173,9 @@ public static void main(String[] args) {
由此可见将 Integer 最大缓存修改为 666 之后,667 不会被缓存,而 -128~666 之间的数都被缓存了。
-### 相关面试题
+## 相关面试题
-#### 1. 以下 Integer 代码输出的结果是?
+### 1. 以下 Integer 代码输出的结果是?
```java
Integer age = 10;
@@ -187,7 +187,7 @@ System.out.println((age == age2) + "," + (age3 == age4));
答:`true,false`
-#### 2. 以下 Double 代码输出的结果是?
+### 2. 以下 Double 代码输出的结果是?
```
Double num = 10d;
@@ -199,7 +199,7 @@ System.out.println((num == num2) + "," + (num3 == num4));
答:`false,false`
-#### 3. 以下程序输出结果是?
+### 3. 以下程序输出结果是?
```java
int i = 100;
@@ -217,7 +217,7 @@ D:false,false
题目分析:有人认为这和 Integer 高速缓存有关系,但你发现把值改为 10000 结果也是 `true,true`,这是因为 Integer 和 int 比较时,会自动拆箱为 int 相当于两个 int 比较,值一定是 `true,true`。
-#### 4. 以下程序执行的结果是?
+### 4. 以下程序执行的结果是?
```java
final int iMax = Integer.MAX_VALUE;
@@ -233,7 +233,7 @@ D:以上都不是
题目解析:这是因为整数在内存中使用的是补码的形式表示,最高位是符号位 0 表示正数,1 表示负数,当执行 +1 时,最高位就变成了 1,结果就成了 -2147483648。
-#### 5. 以下程序执行的结果是?
+### 5. 以下程序执行的结果是?
```java
Set set = new HashSet<>();
@@ -253,36 +253,36 @@ D:以上都不是
题目解析:Short 类型 -1 之后转换成了 Int 类型,remove() 的时候在集合中找不到 Int 类型的数据,所以就没有删除任何元素,执行的结果就是 5。
-#### 6. `short s=2;s=s+1;` 会报错吗?`short s=2;s+=1;` 会报错吗?
+### 6. `short s=2;s=s+1;` 会报错吗?`short s=2;s+=1;` 会报错吗?
答:s=s+1 会报错,s+=1 不会报错,因为 s=s+1 会导致 short 类型升级为 int 类型,所以会报错,而 s+=1 还是原来的 short 类型,所以不会报错。
-#### 7. `float f=3.4;` 会报错吗?为什么?
+### 7. `float f=3.4;` 会报错吗?为什么?
答:会报错,因为值 3.4 是 double 类型,float 类型级别小于 double 类型,所以会报错。如下图所示:

-#### 8. 为什么需要包装类?
+### 8. 为什么需要包装类?
答:需要包装类的原因有两个。
① Java 的设计思想是万物既对象,包装类体现了面向对象的设计理念;
② 包装类包含了很多属性和方法,比基本数据类型功能多,比如提供的获取哈希值(hashCode)或获取类(getClass)的方法等。
-#### 9. 基本类 int 和包装类 Integer,在 -128~127 之间都会复用已有的缓存对象,这种说法正确吗?
+### 9. 基本类 int 和包装类 Integer,在 -128~127 之间都会复用已有的缓存对象,这种说法正确吗?
答:不正确,只有包装类高频区域数据才有缓存。
-#### 10. 包装类 Double 和 Integer 一样都有高频区域数据缓存,这种说法正确吗?
+### 10. 包装类 Double 和 Integer 一样都有高频区域数据缓存,这种说法正确吗?
答:不正确,基本数据类型的包装类只有 Double 和 Float 没有高频区域的缓存。
-#### 11. 包装类的值比较要使用什么方法?
+### 11. 包装类的值比较要使用什么方法?
答:包装类因为有高频区域数据缓存,所以推荐使用 equals() 方法进行值比较。
-#### 12. 包装类有哪些功能?
+### 12. 包装类有哪些功能?
答:包装类提供的功能有以下几个。
@@ -294,11 +294,11 @@ D:以上都不是
详见正文“包装类型”部分内容。
-#### 13. 泛型可以为基本类型吗?为什么?
+### 13. 泛型可以为基本类型吗?为什么?
答:泛型不能使用基本数据类型。泛型在 JVM(Java虚拟机)编译的时候会类型檫除,比如代码 `List list` 在 JVM 编译的时候会转换为 `List list` ,因为泛型是在 JDK 5 时提供的,而 JVM 的类型檫除是为了兼容以前代码的一个折中方案,类型檫除之后就变成了 Object,而 Object 不能存储基本数据类型,但可以使用基本数据类型对应的包装类,所以像 `List list` 这样的代码是不被允许的,编译器阶段会检查报错,而 `List list` 是被允许的。
-#### 14. 选择包装类还是基本类的原则有哪些?
+### 14. 选择包装类还是基本类的原则有哪些?
答:我们知道正确的使用包装类,可以提供程序的执行效率,可以使用已有的缓存,一般情况下选择基本数据类型还是包装类原则有以下几个。
@@ -306,14 +306,14 @@ D:以上都不是
② RPC 方法返回值和参数必须使用包装类;
③ 所有局部变量推荐使用基本数据类型。
-#### 15. 基本数据类型在 JVM 中一定存储在栈中吗?为什么?
+### 15. 基本数据类型在 JVM 中一定存储在栈中吗?为什么?
答:基本数据类型不一定存储在栈中,因为基本类型的存储位置取决于声明的作用域,来看具体的解释。
- 当基本数据类型为局部变量的时候,比如在方法中声明的变量,则存放在方法栈中的,当方法结束系统会释放方法栈,在该方法中的变量也会随着栈的销毁而结束,这也是局部变量只能在方法中使用的原因;
- 当基本数据类型为全局变量的时候,比如类中的声明的变量,则存储在堆上,因为全局变量不会随着某个方法的执行结束而销毁。
-#### 16. 以下程序执行的结果是?
+### 16. 以下程序执行的结果是?
```java
Integer i1 = new Integer(10);
@@ -334,7 +334,7 @@ D:true,false,false
题目解析:new Integer(10) 每次都会创建一个新对象,Integer.valueOf(10) 则会使用缓存池中的对象。
-#### 17. 3*0.1==0.3 返回值是多少?
+### 17. 3*0.1==0.3 返回值是多少?
答:返回值为:false。
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
similarity index 90%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
index 67917a7..7a0e7ad 100644
--- "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
+++ "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\345\274\202\345\270\270\345\244\204\347\220\206.md"
@@ -1,8 +1,8 @@
-## 理解异常处理
+# 理解异常处理
在程序开发中,异常处理也是我们经常使用到的模块,只是平常很少去深究异常模块的一些知识点。比如,try-catch 处理要遵循的原则是什么,finally 为什么总是能执行,try-catch 为什么比较消耗程序的执行性能等问题,我们本讲内容都会给出相应的答案,当然还有面试中经常被问到的异常模块的一些面试题,也是我们本篇要讲解的重点内容。
-### 异常处理基础介绍
+## 异常处理基础介绍
先来看看**异常处理的语法格式**:
@@ -44,7 +44,7 @@ try {

-### 异常处理的发展
+## 异常处理的发展
随着 Java 语言的发展,JDK 7 的时候引入了一些更加便利的特性,用来更方便的处理异常信息,如 try-with-resources 和 multiple catch,具体可以参考下面的代码段:
@@ -57,7 +57,7 @@ try (FileReader fileReader = new FileReader("");
}
```
-### 异常处理的基本原则
+## 异常处理的基本原则
先来看下面这段代码,有没有发现一些问题?
@@ -74,7 +74,7 @@ try {
- 第一,尽量不要捕获通用异常,也就是像 Exception 这样的异常,而是应该捕获特定异常,这样更有助于你发现问题;
- 第二,不要忽略异常,像上面的这段代码只是加了 catch,但没有进行如何的错误处理,信息就已经输出了,这样在程序出现问题的时候,根本找不到问题出现的原因,因此要切记不要直接忽略异常。
-### 异常处理对程序性能的影响
+## 异常处理对程序性能的影响
异常处理固然好用,但一定不要滥用,比如下面的代码片段:
@@ -112,13 +112,13 @@ if (null != jsonStr && !jsonStr.equals("")) {
System.out.println(array.size());
```
-### 相关面试题
+## 相关面试题
-#### 1. try 可以单独使用吗?
+### 1. try 可以单独使用吗?
答:try 不能单独使用,否则就失去了 try 的意义和价值。
-#### 2. 以下 try-catch 可以正常运行吗?
+### 2. 以下 try-catch 可以正常运行吗?
```
try {
@@ -130,7 +130,7 @@ try {
答:不能正常运行,catch 后必须包含异常信息,如 catch (Exception e)。
-#### 3. 以下 try-finally 可以正常运行吗?
+### 3. 以下 try-finally 可以正常运行吗?
```
try {
@@ -142,7 +142,7 @@ try {
答:可以正常运行。
-#### 4. 以下代码 catch 里也发生了异常,程序会怎么执行?
+### 4. 以下代码 catch 里也发生了异常,程序会怎么执行?
```java
try {
@@ -159,7 +159,7 @@ System.out.println("main");
答:程序会打印出 finally 之后抛出异常并终止运行。
-#### 5. 以下代码 finally 里也发生了异常,程序会怎么运行?
+### 5. 以下代码 finally 里也发生了异常,程序会怎么运行?
```
try {
@@ -175,7 +175,7 @@ System.out.println("main");
答:程序在输出 try 之后抛出异常并终止运行,不会再执行 finally 异常之后的代码。
-#### 6. 常见的运行时异常都有哪些?
+### 6. 常见的运行时异常都有哪些?
答:常见的运行时异常如下:
@@ -191,21 +191,21 @@ System.out.println("main");
- java.lang.NoSuchMethodException 方法不存在异常;
- java.lang.IllegalArgumentException 方法传递参数错误。
-#### 7. Exception 和 Error 有什么区别?
+### 7. Exception 和 Error 有什么区别?
答:Exception 和 Error 都属于 Throwable 的子类,在 Java 中只有 Throwable 及其之类才能被捕获或抛出,它们的区别如下:
- Exception(异常)是程序正常运行中,可以预期的意外情况,并且可以使用 try/catch 进行捕获处理的。Exception 又分为运行时异常(Runtime Exception)和受检查的异常(Checked Exception),运行时异常编译能通过,但如果运行过程中出现这类未处理的异常,程序会终止运行;而受检查的异常,要么用 try/catch 捕获,要么用 throws 字句声明抛出,否则编译不会通过。
- Error(错误)是指突发的非正常情况,通常是不可以恢复的,比如 Java 虚拟机内存溢出,诸如此类的问题叫做 Error。
-#### 8. throw 和 throws 的区别是什么?
+### 8. throw 和 throws 的区别是什么?
答:它们的区别如下:
- throw 语句用在方法体内,表示抛出异常由方法体内的语句处理,执行 throw 一定是抛出了某种异常;
- throws 语句用在方法声明的后面,该方法的调用者要对异常进行处理,throws 代表可能会出现某种异常,并不一定会发生这种异常。
-#### 9. Integer.parseInt(null) 和 Double.parseDouble(null) 抛出的异常一样吗?为什么?
+### 9. Integer.parseInt(null) 和 Double.parseDouble(null) 抛出的异常一样吗?为什么?
答:Integer.parseInt(null) 和 Double.parseDouble(null) 抛出的异常类型不一样,如下所示:
@@ -214,17 +214,17 @@ System.out.println("main");
至于为什么会产生不同的异常,其实没有特殊的原因,主要是由于这两个功能是不同人开发的,因而就产生了两种不同的异常信息。
-#### 10. NoClassDefFoundError 和 ClassNoFoundException 有什么区别?
+### 10. NoClassDefFoundError 和 ClassNoFoundException 有什么区别?
- NoClassDefFoundError 是 Error(错误)类型,而 ClassNoFoundExcept 是 Exception(异常)类型;
- ClassNoFoundExcept 是 Java 使用 Class.forName 方法动态加载类,没有加载到,就会抛出 ClassNoFoundExcept 异常;
- NoClassDefFoundError 是 Java 虚拟机或者 ClassLoader 尝试加载类的时候却找不到类订阅导致的,也就是说要查找的类在编译的时候是存在的,运行的时候却找不到,这个时候就会出现 NoClassDefFoundError 的错误。
-#### 11. 使用 try-catch 为什么比较耗费性能?
+### 11. 使用 try-catch 为什么比较耗费性能?
答:这个问题要从 JVM(Java 虚拟机)层面找答案了。首先 Java 虚拟机在构造异常实例的时候需要生成该异常的栈轨迹,这个操作会逐一访问当前线程的栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常等信息,这就是使用异常捕获耗时的主要原因了。
-#### 12. 常见的 OOM 原因有哪些?
+### 12. 常见的 OOM 原因有哪些?
答:常见的 OOM 原因有以下几个:
@@ -232,7 +232,7 @@ System.out.println("main");
- 加载特别大的图片;
- 递归次数过多,并一直操作未释放的变量。
-#### 13. 以下程序的返回结果是?
+### 13. 以下程序的返回结果是?
```java
public static int getNumber() {
@@ -257,13 +257,13 @@ D:1
题目解析:程序最后一定会执行 finally 里的代码,会把之前的结果覆盖为 3。
-#### 14. finally、finalize 的区别是什么?
+### 14. finally、finalize 的区别是什么?
答:finally、finalize 的区别如下:
- finally 是异常处理语句的一部分,表示总是执行;
- finalize 是 Object 类的一个方法,子类可以覆盖该方法以实现资源清理工作,垃圾回收之前会调用此方法。
-#### 15. 为什么 finally 总能被执行?
+### 15. 为什么 finally 总能被执行?
答:finally 总会被执行,都是编译器的作用,因为编译器在编译 Java 代码时,会复制 finally 代码块的内容,然后分别放在 try-catch 代码块所有的正常执行路径及异常执行路径的出口中,这样 finally 才会不管发生什么情况都会执行。
\ No newline at end of file
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\212\275\350\261\241\347\261\273\344\270\216\346\216\245\345\217\243.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\225\260\346\215\256\347\273\223\346\236\204\351\230\237\345\210\227.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\263\233\345\236\213\344\270\216\350\277\255\344\273\243\345\231\250.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\346\265\205\345\205\213\351\232\206\345\222\214\346\267\261\345\205\213\351\232\206.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\347\261\273\344\270\216Object.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\347\261\273\344\270\216Object.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\347\261\273\344\270\216Object.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\347\261\273\344\270\216Object.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Collection.md"
diff --git "a/docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Map.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Map.md"
similarity index 100%
rename from "docs/Java\344\270\207\345\262\201/Java-\345\237\272\347\241\200\344\270\215\347\211\242\345\234\260\345\212\250\345\261\261\346\221\207/\347\220\206\350\247\243\351\233\206\345\220\210Map.md"
rename to "docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\233\206\345\220\210Map.md"
diff --git "a/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\235\242\345\220\221\345\257\271\350\261\241.md" "b/docs/Java\346\240\270\345\277\203\345\237\272\347\241\200/\347\220\206\350\247\243\351\235\242\345\220\221\345\257\271\350\261\241.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md"
index 1926745..36851e0 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ArrayList\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,8 +1,4 @@
-
-
-
-
-# ArrayList源码分析
+# 👉 ArrayList源码分析
## 1 底层结构
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index e32c62d..0c646d3 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/ConcurrentHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-## ConcurrentHashMap源码分析
+# 👉 ConcurrentHashMap源码分析
当我们碰到线程不安全场景下,需要使用 Map 的时候,我们第一个想到的 API 估计就是 ConcurrentHashMap,ConcurrentHashMap 内部封装了锁和各种数据结构来保证访问 Map 是线程安全的,接下来我们一一来看下,和 HashMap 相比,多了哪些数据结构,又是如何保证线程安全的。
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index f578794..a648254 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-## HashMap源码分析
+# 👉 HashMap源码分析
## 1 整体架构
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md"
index c83671a..cc56b9d 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/HashSet\344\270\216TreeSet\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-## HashSet与TreeSet
+# 👉 HashSet与TreeSet
HashSet、TreeSet 两个类是在 Map 的基础上组装起来的类,我们学习的侧重点,主要在于 Set 是如何利用 Map 现有的功能,来达成自己的目标的,也就是说如何基于现有的功能进行创新,然后再看看一些改变的小细节是否值得我们学习。
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index ecd3e53..897ddbb 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/LinkedHashMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-# LinkedHashMap源码分析
+# 👉 LinkedHashMap源码分析
HashMap 是无序的,TreeMap 可以按照 key 进行排序,那有木有 Map 是可以维护插入的顺序的呢?接下来我们一起来看下 LinkedHashMap。
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/README.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/README.md"
new file mode 100644
index 0000000..a788b3f
--- /dev/null
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/README.md"
@@ -0,0 +1,8 @@
+# Java并发编程
+
+* [ArrayList源码分析](docs/Java源码分析/ArrayList源码分析.md)
+* [HashMap源码分析](docs/Java源码分析/HashMap源码分析.md)
+* [HashSet与TreeSet源码分析](docs/Java源码分析/HashSet与TreeSet源码分析.md)
+* [LinkedHashMap源码分析](docs/Java源码分析/LinkedHashMap源码分析.md)
+* [TreeMap源码分析](docs/Java源码分析/TreeMap源码分析.md)
+
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
index 58715aa..5db0820 100644
--- "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/TreeMap\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -1,4 +1,4 @@
-# TreeMap源码分析
+# 👉 TreeMap源码分析
## 1 知识储备
diff --git "a/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/_sidebar.md" "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/_sidebar.md"
new file mode 100644
index 0000000..bf4f932
--- /dev/null
+++ "b/docs/Java\346\272\220\347\240\201\345\210\206\346\236\220/_sidebar.md"
@@ -0,0 +1,6 @@
+* **👉 Java源码分析** [↩](/README)
+ * [ArrayList源码分析](docs/Java源码分析/ArrayList源码分析.md)
+ * [HashMap源码分析](docs/Java源码分析/HashMap源码分析.md)
+ * [HashSet与TreeSet源码分析](docs/Java源码分析/HashSet与TreeSet源码分析.md)
+ * [LinkedHashMap源码分析](docs/Java源码分析/LinkedHashMap源码分析.md)
+ * [TreeMap源码分析](docs/Java源码分析/TreeMap源码分析.md)
\ No newline at end of file
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md"
new file mode 100644
index 0000000..596b465
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/JVM\347\241\256\350\256\244\345\217\257\345\233\236\346\224\266\345\257\271\350\261\241\347\232\204\346\226\271\345\274\217.md"
@@ -0,0 +1,110 @@
+# 👉 JVM确认可回收对象的方式
+
+## 前言
+
+在开始之前,我们先回顾一下`堆`是个什么玩意,大家可能都知道,我们每天创建的Java对象几乎都存放在堆上面,所以说堆是一个巨大的对象池一点都不过分,在这个对象池里面管理者数据巨大的对象实例。
+
+在对象池中对象的引用层次,有的是很深的。比如一个调用非常频繁的接口,生产对象的速度是非常可观的。对象之间的关系,可以形容成一张网。虽然Java总是给人一种有使不完的内存的感觉,但是对象也不能一直增加不减少啊,所以就必须有**垃圾回收**这个操作。
+
+## JVM是怎么认识`垃圾`的呢?
+
+**"垃圾回收"本文中简称 GC**
+
+你还记得电视剧中的“诛九族""?
+
+ +
+比如小憨批打了皇帝老儿一巴掌,把皇帝老儿打的鼻青脸肿滴,皇帝老儿非常生气,他要下令诛小憨批的九族,以平心头只恨。
+
+哈哈哈嗝~ 小憨批完了~
+
+
+
+比如小憨批打了皇帝老儿一巴掌,把皇帝老儿打的鼻青脸肿滴,皇帝老儿非常生气,他要下令诛小憨批的九族,以平心头只恨。
+
+哈哈哈嗝~ 小憨批完了~
+
+ +
+那么我们看看在古代这个诛九族是具体操作的呢?首先需要追溯到共同的祖先(也就是小憨批家族的大哥大),再往下逐一细数和小憨批有关系的(小憨批真坑啊)。
+
+
+
+那么我们看看在古代这个诛九族是具体操作的呢?首先需要追溯到共同的祖先(也就是小憨批家族的大哥大),再往下逐一细数和小憨批有关系的(小憨批真坑啊)。
+
+ +
+
+
+其实发生在堆上的垃圾回收和这个“诛九族“的是相同思路,那么我们下面具体分析一下JVM是如何进行GC的呢?
+
+**关于JVM的GC是不受程序控制的,当满足一定条件的时候就会主动触发。**
+
+当发生GC的时候,对于一个对象来说,JVM总能够找到引用它的祖先,当找到最后的时候,JVM发现这家伙的有些祖先已经玩完了,那么它们就会被JVM给干掉。
+
+为什么还有没有被干掉的祖先呢?因为这些躲过GC的祖先们,它们是GC Roots ,长得比较特殊嘛。
+
+当从GC Roots 向下追溯、搜索,就会产生一个引用链。当碰到有对象没有任何一个GC Roots 产生关系的话,这个对象就会被无情的干掉。(一根绳上的蚂蚱嘛)
+
+来,我们画个图瞅瞅咋回事,如下图所示,Obj5、Obj6、Obj7,由于不能和 GC Root 产生关联,发生 GC 时,就会被摧毁。
+
+
+
+
+
+其实发生在堆上的垃圾回收和这个“诛九族“的是相同思路,那么我们下面具体分析一下JVM是如何进行GC的呢?
+
+**关于JVM的GC是不受程序控制的,当满足一定条件的时候就会主动触发。**
+
+当发生GC的时候,对于一个对象来说,JVM总能够找到引用它的祖先,当找到最后的时候,JVM发现这家伙的有些祖先已经玩完了,那么它们就会被JVM给干掉。
+
+为什么还有没有被干掉的祖先呢?因为这些躲过GC的祖先们,它们是GC Roots ,长得比较特殊嘛。
+
+当从GC Roots 向下追溯、搜索,就会产生一个引用链。当碰到有对象没有任何一个GC Roots 产生关系的话,这个对象就会被无情的干掉。(一根绳上的蚂蚱嘛)
+
+来,我们画个图瞅瞅咋回事,如下图所示,Obj5、Obj6、Obj7,由于不能和 GC Root 产生关联,发生 GC 时,就会被摧毁。
+
+ +
+
+
+其实所谓的垃圾回收就是围绕着GC Roots 来的,但是同时,GC Roots 也存在着很多内存泄漏的根源,因为其他引用小弟压根没有这个权利。
+
+那么什么样的对象才会是GC Roots 呢? 这个不在于它是什么样的对象,关键是它所处的位置(仔细品~)。
+
+## GC Roots 是什么
+
+首先,GC Roots必须是一组必须活跃的引用。简单的讲,就是程序接下来通过直接引用或间接引用,能够被访问到的潜在被使用的对象(咋感觉还是有点绕呢)。
+
+**GC Roots:**
+
+1. Java线程中,当前所有正在被调用的方法的引用类型参数、局部变量、临时值等等。也就是与我们栈帧相关的各种引用。
+2. 所有当前被加载的Java类。
+3. Java类的引用类型静态变量。
+4. 运行时常量池里的引用类型常量。
+5. JVM内部数据结构的一些引用,比如sun.jvm.hotspot.memory.Univers类。
+6. 用于同步的监控对象。比如调用了对象的wait()方法。
+7. JNI handles,包括global handles 和 local handles。
+
+以上GC Roots大致可以分为一下三大类。
+
+1. 活动线程相关的各种引用。
+2. 类的静态变量的引用。
+3. JNI引用。
+
+最后我们需要注意的是,我们这里说的是活跃的引用,而不是对象,对象是不能作为GC Roots的。
+
+整个GC过程中是找到那些活对象,并把剩余的空间都认得为“无用”。而不是找到所有死掉的对象,并回收它们占用的空间。所有说,哪怕JVM的堆非常大,基于tracing的GC方式,回收速度也是跟快的。
+
+## 总结
+
+ GC Roots 就是可达性分析法。还有一种叫作引用计数法的方式。下面我们简单介绍一下。
+
+引用计数法:在Java中如果要操作对象,就必须先获取该对象的引用,因此可以通过引用计数法来判断一个对象是否可以被回收。在为一个对象添加一个引用时,引用计数器就加1;为对象删除一个引用时,引用计数器就减1;如果一个对象的引用计数为0,则说明该对象没有被引用,可以回收。**优点是垃圾回收比较及时,实时性比较高,只要对象计数器为 0,则可以直接进行回收操作;而缺点是无法解决循环引用的问题。**
+
+因为存在循环引用这个致命的硬伤,没有一个是采用引用计数法来实现 GC 的,所有你现在完全忘记引用计数这种方式了。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md"
new file mode 100644
index 0000000..d5931c9
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md"
@@ -0,0 +1,36 @@
+# 👉 JVM的内存区域
+
+ **线程私有区域**的生命周期与线程相同,随线程的启动而创建,随线程的启动而创建,随线程的结束而销毁。在JVM内部,每个线程都与操作系统的本地线程直接映射,因此线程私有内存区域的存在与否和本地线程的启动和销毁对应。
+
+ **线程共享区域**随虚拟机的启动而创建,随虚拟机的关闭而销毁。
+
+## 程序计数器 : 线程私有,无内存溢出问题
+
+ 程序计数器是一块很小的内存空间,用于存储当前运行的线程所执行的字节码的行号指令,每个运行中的线程都有一个独立的程序计数器,在方法正在执行时,该方法的程序计数器记录的是实时虚拟机字节码指令的地址;如果该方法执行的是Native方法,则程序计数器的值为空。
+
+ 程序计数器是唯一没有内存溢出的区域。
+
+## 虚拟机栈 : 线程私有,描述Java方法的执行过程
+
+ 虚拟机栈是描述Java方法的执行过程的内存模型,它在当前栈帧存储了局部变量表、操作数栈、动态链接、方法出口等信息。同时,栈帧用来存储部分运行时数据及其数据结构,处理动态链接方法的返回值和异常分派。
+
+ 栈帧用来记录方法的执行过程,在方法被执行时虚拟机会为其创建一个与之对应的栈帧,方法的执行和返回对应栈帧在虚拟机中的入栈和出栈。无法方法是正常运行完成还是异常完成,都可以视为方法运行结束。
+
+## 本地方法区 : 线程私有
+
+ 本地方法区和虚拟机栈作用类似,区别就是本地方法栈是为Native方法服务,而虚拟机栈是为了Java方法服务。
+
+## 堆内存 : 线程共享,运行时数据区
+
+ 在JVM运行过程中创建的对象和产生的数据都被存储在堆中,堆是被线程共享的内存区域,也是垃圾收集器进行垃圾回首的最主要的内存区域。
+
+## 方法区 :线程共享
+
+ 方法区用于存储常量、静态变量、类信息、即时编译器编译后的机器码、运行时常量池等数据。
+
+ JVM把GC分代收集扩展至方法区,即使用Java堆的永久代来实现方法区,这样JVM的垃圾收集器就可以像管理Java堆一样管理这部分内存。永久带的内存回收主要针对常量池的回收和类的卸载,因此可回收的对象很少。
+
+ 常量被存储在运行时常量池中,是方法区的一部分。静态也属于方法区的一部分。在类信息中不但保存了类的版本/字段/方法/接口等描述信息,还保存了常量信息。
+
+ 在即使编译后,代码的内容将在执行阶段被保存在方法区的运行时常量池中。Java虚拟机堆Class文件每一部分的格式都明确的规定,只有符合规范的Class文件才能通过虚拟机的检查,然后被装载和执行。
+
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/README.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/README.md"
new file mode 100644
index 0000000..bac0e28
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/README.md"
@@ -0,0 +1,9 @@
+# JVM虚拟机
+
+ * [Java运行时内存划分](docs/Java虚拟机/Java运行时内存划分.md)
+ * [JVM确认可回收对象的方式](docs/Java虚拟机/JVM确认可回收对象的方式.md)
+ * [类加载机制](docs/Java虚拟机/类加载机制.md)
+ * [双亲委派机制](docs/Java虚拟机/双亲委派机制.md)
+ * [四种引用类型](docs/Java虚拟机/四种引用类型.md)
+ * [垃圾回收器](docs/Java虚拟机/垃圾回收器.md)
+ * [垃圾回收算法](docs/Java虚拟机/Jav垃圾回收算法a运行时内存划分.md)
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/_sidebar.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/_sidebar.md"
new file mode 100644
index 0000000..890d76e
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/_sidebar.md"
@@ -0,0 +1,8 @@
+* **👉 Java虚拟机** [↩](/README)
+ * [Java运行时内存划分](docs/Java虚拟机/Java运行时内存划分.md)
+ * [JVM确认可回收对象的方式](docs/Java虚拟机/JVM确认可回收对象的方式.md)
+ * [类加载机制](docs/Java虚拟机/类加载机制.md)
+ * [双亲委派机制](docs/Java虚拟机/双亲委派机制.md)
+ * [四种引用类型](docs/Java虚拟机/四种引用类型.md)
+ * [垃圾回收器](docs/Java虚拟机/垃圾回收器.md)
+ * [垃圾回收算法](docs/Java虚拟机/Jav垃圾回收算法a运行时内存划分.md)
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/\345\217\214\344\272\262\345\247\224\346\264\276\346\234\272\345\210\266.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\217\214\344\272\262\345\247\224\346\264\276\346\234\272\345\210\266.md"
new file mode 100644
index 0000000..82b9862
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\217\214\344\272\262\345\247\224\346\264\276\346\234\272\345\210\266.md"
@@ -0,0 +1,17 @@
+# 👉 双亲委派机制
+
+ 双亲委派机制是指一个类在收到类加载请求之后不会尝试自己加载这个类,而是把该类加载请求向上委派给其父类,其父类在接受到该类的加载请求之后又会将其委派给自己的父类,以此类推,这样所有的类加载请求都被向上委派到启动类加载器中。
+
+ 但是若父类加载器在接收到类加载请求后发现自己也无法加载该类,则父类会将该信息反馈给子类并向下委派子类加载器,直到该类被成功加载,若找不到该类,则JVM会抛出ClassNotFind异常。
+
+ **双亲委派加载机制的类加载流程。**
+
+1. 将自定义加载器挂载到应用程序类加载器。
+2. 应用程序类加载器将类加载请求委托给扩展类加载器。
+3. 扩展器加载器将类加载请求委托给启动类加载器。
+4. 启动类加载器在加载路径下查找并加载Class文件,如果未找到目标Class文件,则交给应用程序类加载器加载。
+5. 扩张类加载器在加载路径下查找并加载Class文件,如果未找到目标Class文件,则交由应用程序类加载器加载。
+6. 应用程序类加载器在加载路径下查找并加载Class文件,如果未找到目标Class文件,则交由自定义类加载器加载。
+7. 在自定义加载器下查找并加载用户指定目录下的Class文件,如果在自定义加载路径下为找到目标Class文件,则抛出ClassNotFind异常。
+
+ **双亲委派加载机制的核心就是保证类的唯一性和安全性。**
\ No newline at end of file
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/\345\233\233\347\247\215\345\274\225\347\224\250\347\261\273\345\236\213.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\233\233\347\247\215\345\274\225\347\224\250\347\261\273\345\236\213.md"
new file mode 100644
index 0000000..1bfca77
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\233\233\347\247\215\345\274\225\347\224\250\347\261\273\345\236\213.md"
@@ -0,0 +1,114 @@
+# 👉 四种引用类型
+Java中一切皆为对象,Java中的引用类型有四种,分别为强引用/软引用/弱引用/虚引用等。
+
+## 强引用—trong references
+
+当内存空间不足,系统撑不住了,JVM 就会抛出 OutOfMemoryError 错误。即使程序会异常终止,这种对象也不会被回收。这种引用属于最普通最强硬的一种存在,只有在和 GC Roots 断绝关系时,才会被消灭掉。
+
+这种引用,你每天的编码都在用。例如:new 一个普通的对象。
+
+```java
+Object obj = new Object()
+```
+
+这种方式可能是有问题的。假如你的系统被大量用户(User)访问,你需要记录这个 User 访问的时间。可惜的是,User 对象里并没有这个字段,所以我们决定将这些信息额外开辟一个空间进行存放。
+
+```java
+static Map userVisitMap = new HashMap<>();
+
+...
+
+userVisitMap.put(user, time);
+```
+
+当你用完了 User 对象,其实你是期望它被回收掉的。但是,由于它被 userVisitMap 引用,我们没有其他手段 remove 掉它。这个时候,就发生了内存泄漏(memory leak)。
+
+这种情况还通常发生在一个没有设定上限的 Cache 系统,由于设置了不正确的引用方式,加上不正确的容量,很容易造成 OOM。
+
+## 软引用—Soft references
+
+软引用用于维护一些可有可无的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。
+
+可以看到,这种特性非常适合用在缓存技术上。比如网页缓存、图片缓存等。
+
+Guava 的 CacheBuilder,就提供了软引用和弱引用的设置方式。在这种场景中,软引用比强引用安全的多。
+
+软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java 虚拟机就会把这个软引用加入到与之关联的引用队列中。
+
+我们可以看一下它的代码。软引用需要显式的声明,使用泛型来实现。
+
+```java
+// 伪代码
+
+Object object = new Object();
+
+SoftReference
+
+
+
+其实所谓的垃圾回收就是围绕着GC Roots 来的,但是同时,GC Roots 也存在着很多内存泄漏的根源,因为其他引用小弟压根没有这个权利。
+
+那么什么样的对象才会是GC Roots 呢? 这个不在于它是什么样的对象,关键是它所处的位置(仔细品~)。
+
+## GC Roots 是什么
+
+首先,GC Roots必须是一组必须活跃的引用。简单的讲,就是程序接下来通过直接引用或间接引用,能够被访问到的潜在被使用的对象(咋感觉还是有点绕呢)。
+
+**GC Roots:**
+
+1. Java线程中,当前所有正在被调用的方法的引用类型参数、局部变量、临时值等等。也就是与我们栈帧相关的各种引用。
+2. 所有当前被加载的Java类。
+3. Java类的引用类型静态变量。
+4. 运行时常量池里的引用类型常量。
+5. JVM内部数据结构的一些引用,比如sun.jvm.hotspot.memory.Univers类。
+6. 用于同步的监控对象。比如调用了对象的wait()方法。
+7. JNI handles,包括global handles 和 local handles。
+
+以上GC Roots大致可以分为一下三大类。
+
+1. 活动线程相关的各种引用。
+2. 类的静态变量的引用。
+3. JNI引用。
+
+最后我们需要注意的是,我们这里说的是活跃的引用,而不是对象,对象是不能作为GC Roots的。
+
+整个GC过程中是找到那些活对象,并把剩余的空间都认得为“无用”。而不是找到所有死掉的对象,并回收它们占用的空间。所有说,哪怕JVM的堆非常大,基于tracing的GC方式,回收速度也是跟快的。
+
+## 总结
+
+ GC Roots 就是可达性分析法。还有一种叫作引用计数法的方式。下面我们简单介绍一下。
+
+引用计数法:在Java中如果要操作对象,就必须先获取该对象的引用,因此可以通过引用计数法来判断一个对象是否可以被回收。在为一个对象添加一个引用时,引用计数器就加1;为对象删除一个引用时,引用计数器就减1;如果一个对象的引用计数为0,则说明该对象没有被引用,可以回收。**优点是垃圾回收比较及时,实时性比较高,只要对象计数器为 0,则可以直接进行回收操作;而缺点是无法解决循环引用的问题。**
+
+因为存在循环引用这个致命的硬伤,没有一个是采用引用计数法来实现 GC 的,所有你现在完全忘记引用计数这种方式了。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md"
new file mode 100644
index 0000000..d5931c9
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/Java\350\277\220\350\241\214\346\227\266\345\206\205\345\255\230\345\210\222\345\210\206.md"
@@ -0,0 +1,36 @@
+# 👉 JVM的内存区域
+
+ **线程私有区域**的生命周期与线程相同,随线程的启动而创建,随线程的启动而创建,随线程的结束而销毁。在JVM内部,每个线程都与操作系统的本地线程直接映射,因此线程私有内存区域的存在与否和本地线程的启动和销毁对应。
+
+ **线程共享区域**随虚拟机的启动而创建,随虚拟机的关闭而销毁。
+
+## 程序计数器 : 线程私有,无内存溢出问题
+
+ 程序计数器是一块很小的内存空间,用于存储当前运行的线程所执行的字节码的行号指令,每个运行中的线程都有一个独立的程序计数器,在方法正在执行时,该方法的程序计数器记录的是实时虚拟机字节码指令的地址;如果该方法执行的是Native方法,则程序计数器的值为空。
+
+ 程序计数器是唯一没有内存溢出的区域。
+
+## 虚拟机栈 : 线程私有,描述Java方法的执行过程
+
+ 虚拟机栈是描述Java方法的执行过程的内存模型,它在当前栈帧存储了局部变量表、操作数栈、动态链接、方法出口等信息。同时,栈帧用来存储部分运行时数据及其数据结构,处理动态链接方法的返回值和异常分派。
+
+ 栈帧用来记录方法的执行过程,在方法被执行时虚拟机会为其创建一个与之对应的栈帧,方法的执行和返回对应栈帧在虚拟机中的入栈和出栈。无法方法是正常运行完成还是异常完成,都可以视为方法运行结束。
+
+## 本地方法区 : 线程私有
+
+ 本地方法区和虚拟机栈作用类似,区别就是本地方法栈是为Native方法服务,而虚拟机栈是为了Java方法服务。
+
+## 堆内存 : 线程共享,运行时数据区
+
+ 在JVM运行过程中创建的对象和产生的数据都被存储在堆中,堆是被线程共享的内存区域,也是垃圾收集器进行垃圾回首的最主要的内存区域。
+
+## 方法区 :线程共享
+
+ 方法区用于存储常量、静态变量、类信息、即时编译器编译后的机器码、运行时常量池等数据。
+
+ JVM把GC分代收集扩展至方法区,即使用Java堆的永久代来实现方法区,这样JVM的垃圾收集器就可以像管理Java堆一样管理这部分内存。永久带的内存回收主要针对常量池的回收和类的卸载,因此可回收的对象很少。
+
+ 常量被存储在运行时常量池中,是方法区的一部分。静态也属于方法区的一部分。在类信息中不但保存了类的版本/字段/方法/接口等描述信息,还保存了常量信息。
+
+ 在即使编译后,代码的内容将在执行阶段被保存在方法区的运行时常量池中。Java虚拟机堆Class文件每一部分的格式都明确的规定,只有符合规范的Class文件才能通过虚拟机的检查,然后被装载和执行。
+
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/README.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/README.md"
new file mode 100644
index 0000000..bac0e28
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/README.md"
@@ -0,0 +1,9 @@
+# JVM虚拟机
+
+ * [Java运行时内存划分](docs/Java虚拟机/Java运行时内存划分.md)
+ * [JVM确认可回收对象的方式](docs/Java虚拟机/JVM确认可回收对象的方式.md)
+ * [类加载机制](docs/Java虚拟机/类加载机制.md)
+ * [双亲委派机制](docs/Java虚拟机/双亲委派机制.md)
+ * [四种引用类型](docs/Java虚拟机/四种引用类型.md)
+ * [垃圾回收器](docs/Java虚拟机/垃圾回收器.md)
+ * [垃圾回收算法](docs/Java虚拟机/Jav垃圾回收算法a运行时内存划分.md)
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/_sidebar.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/_sidebar.md"
new file mode 100644
index 0000000..890d76e
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/_sidebar.md"
@@ -0,0 +1,8 @@
+* **👉 Java虚拟机** [↩](/README)
+ * [Java运行时内存划分](docs/Java虚拟机/Java运行时内存划分.md)
+ * [JVM确认可回收对象的方式](docs/Java虚拟机/JVM确认可回收对象的方式.md)
+ * [类加载机制](docs/Java虚拟机/类加载机制.md)
+ * [双亲委派机制](docs/Java虚拟机/双亲委派机制.md)
+ * [四种引用类型](docs/Java虚拟机/四种引用类型.md)
+ * [垃圾回收器](docs/Java虚拟机/垃圾回收器.md)
+ * [垃圾回收算法](docs/Java虚拟机/Jav垃圾回收算法a运行时内存划分.md)
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/\345\217\214\344\272\262\345\247\224\346\264\276\346\234\272\345\210\266.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\217\214\344\272\262\345\247\224\346\264\276\346\234\272\345\210\266.md"
new file mode 100644
index 0000000..82b9862
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\217\214\344\272\262\345\247\224\346\264\276\346\234\272\345\210\266.md"
@@ -0,0 +1,17 @@
+# 👉 双亲委派机制
+
+ 双亲委派机制是指一个类在收到类加载请求之后不会尝试自己加载这个类,而是把该类加载请求向上委派给其父类,其父类在接受到该类的加载请求之后又会将其委派给自己的父类,以此类推,这样所有的类加载请求都被向上委派到启动类加载器中。
+
+ 但是若父类加载器在接收到类加载请求后发现自己也无法加载该类,则父类会将该信息反馈给子类并向下委派子类加载器,直到该类被成功加载,若找不到该类,则JVM会抛出ClassNotFind异常。
+
+ **双亲委派加载机制的类加载流程。**
+
+1. 将自定义加载器挂载到应用程序类加载器。
+2. 应用程序类加载器将类加载请求委托给扩展类加载器。
+3. 扩展器加载器将类加载请求委托给启动类加载器。
+4. 启动类加载器在加载路径下查找并加载Class文件,如果未找到目标Class文件,则交给应用程序类加载器加载。
+5. 扩张类加载器在加载路径下查找并加载Class文件,如果未找到目标Class文件,则交由应用程序类加载器加载。
+6. 应用程序类加载器在加载路径下查找并加载Class文件,如果未找到目标Class文件,则交由自定义类加载器加载。
+7. 在自定义加载器下查找并加载用户指定目录下的Class文件,如果在自定义加载路径下为找到目标Class文件,则抛出ClassNotFind异常。
+
+ **双亲委派加载机制的核心就是保证类的唯一性和安全性。**
\ No newline at end of file
diff --git "a/docs/Java\350\231\232\346\213\237\346\234\272/\345\233\233\347\247\215\345\274\225\347\224\250\347\261\273\345\236\213.md" "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\233\233\347\247\215\345\274\225\347\224\250\347\261\273\345\236\213.md"
new file mode 100644
index 0000000..1bfca77
--- /dev/null
+++ "b/docs/Java\350\231\232\346\213\237\346\234\272/\345\233\233\347\247\215\345\274\225\347\224\250\347\261\273\345\236\213.md"
@@ -0,0 +1,114 @@
+# 👉 四种引用类型
+Java中一切皆为对象,Java中的引用类型有四种,分别为强引用/软引用/弱引用/虚引用等。
+
+## 强引用—trong references
+
+当内存空间不足,系统撑不住了,JVM 就会抛出 OutOfMemoryError 错误。即使程序会异常终止,这种对象也不会被回收。这种引用属于最普通最强硬的一种存在,只有在和 GC Roots 断绝关系时,才会被消灭掉。
+
+这种引用,你每天的编码都在用。例如:new 一个普通的对象。
+
+```java
+Object obj = new Object()
+```
+
+这种方式可能是有问题的。假如你的系统被大量用户(User)访问,你需要记录这个 User 访问的时间。可惜的是,User 对象里并没有这个字段,所以我们决定将这些信息额外开辟一个空间进行存放。
+
+```java
+static Map userVisitMap = new HashMap<>();
+
+...
+
+userVisitMap.put(user, time);
+```
+
+当你用完了 User 对象,其实你是期望它被回收掉的。但是,由于它被 userVisitMap 引用,我们没有其他手段 remove 掉它。这个时候,就发生了内存泄漏(memory leak)。
+
+这种情况还通常发生在一个没有设定上限的 Cache 系统,由于设置了不正确的引用方式,加上不正确的容量,很容易造成 OOM。
+
+## 软引用—Soft references
+
+软引用用于维护一些可有可无的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。
+
+可以看到,这种特性非常适合用在缓存技术上。比如网页缓存、图片缓存等。
+
+Guava 的 CacheBuilder,就提供了软引用和弱引用的设置方式。在这种场景中,软引用比强引用安全的多。
+
+软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java 虚拟机就会把这个软引用加入到与之关联的引用队列中。
+
+我们可以看一下它的代码。软引用需要显式的声明,使用泛型来实现。
+
+```java
+// 伪代码
+
+Object object = new Object();
+
+SoftReference