. * . . . *
* . . .
___
.-´ `-. . *
/ .-~-. \ .
. | / \ | *
| \ / |
\ '-~-' / .
'-.___.-'
. * . .
___ ____ ___ _ _ ___
/ _ \ | _ \ / _ \ | | | | / _ \
| |_| | | |_) | | | || | | | | | | |
| _ | | __/| |_| || |___ | |___| |_| |
|_| |_| |_| \___/ |_____||_____|\___/
~ your HP S100 digital twin ~
Apollo is a physics-grounded, agent-driven digital twin for an industrial metal binder-jet 3-D printer (HP Metal Jet S100 class). It simulates 6 components across 3 subsystems with literature-anchored failure physics, watches three parallel cascades unfold over a ~10-hour print cycle, and lets a tool-using LLM agent answer operator questions with zero hallucinations by construction — every claim must resolve against a real row in the historian or the response is downgraded to a structured refusal.
It is built around 22 Architecture Decision Records that pick the unfashionable-but-defensible tool every time: a 6×6 NumPy matrix instead of a Bayesian network, a Genetic Algorithm instead of RL, simulator deepcopy instead of causal-DAG inference, late-interaction retrieval instead of dense embeddings, and a 31B open model with a GEPA-evolved prompt instead of a frontier closed model.
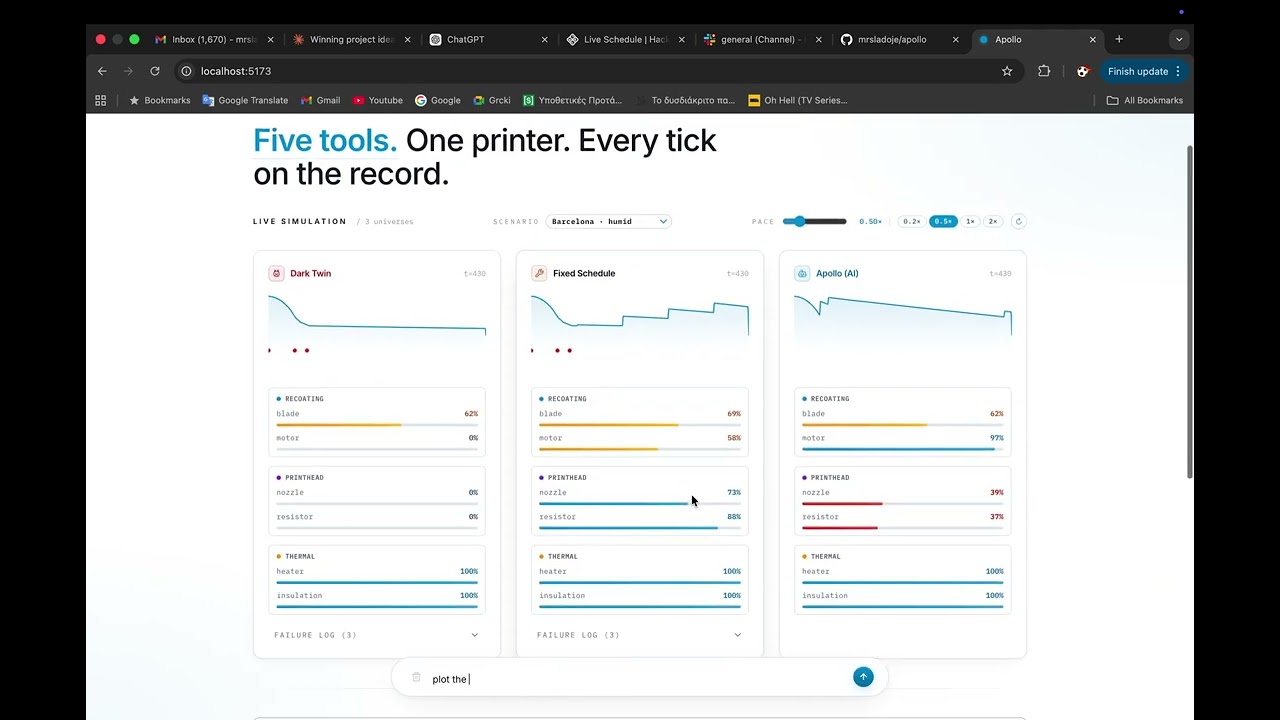
Click on the image above to watch the full demo!
🔬 Simulates a printer's slow death, in physics. Six components — recoater blade, drive motor, nozzle plate, firing resistors, heating element, insulation panel — degrade under three real failure-model families (exponential, Weibull, Coffin-Manson). Each parameter is anchored to published binder-jetting / additive-manufacturing literature, not invented.
🔥 Trains a Physics-Informed Neural Network (DeepXDE on PyTorch+MPS) for the heating element. The 1-D heat-diffusion PDE residual lives in the loss function — the heater can't violate physics, the PDE residual is in its loss.
🕸️ Couples components with a single 6×6 matrix M. One formula, one slide: dH_i/dt = -α_i · f(drivers_i) − Σ_j M_ij · (1 − H_j). Three named cascades (CSC-A recoating loop, CSC-B thermal/printhead showpiece, CSC-C powder contamination) emerge from this matrix plus explicit Arrhenius / Coffin-Manson physics on the showpiece.
🌑 Runs the "Dark Twin" benchmark — three scenarios (Barcelona-humid, Phoenix-dry, Stressed) × three policies (NONE / FIXED / AI). The NONE column is the alternate universe where Apollo wasn't watching, and its component obituaries are the demo's emotional anchor.
🧬 Evolves the maintenance policy with a Genetic Algorithm (DEAP, 7-dim threshold vector, island model with elitism + migration + random immigrants) — the live fitness curve is the demo asset, not a side effect.
🤖 Answers questions agentically (Pattern C). The agent gets exactly five tools — query_historian, late_interaction_search, compare_runs, run_counterfactual, plot_component_history — and streams its tool calls to the UI as they execute, so judges see the reasoning, not just the answer.
🔁 Replays counterfactuals exactly, not statistically. Because we own the simulator, "what if you'd swapped the blade at 04:00?" is a deepcopy + branch + diff, not a causal-inference estimate.
📏 Calibrates every forecast. MAPIE's MapieTimeSeriesRegressor (EnbPi block-bootstrap) wraps each predictor — rule-based or PINN — to produce a 95 % CI band: "heater fails in 8.0 h ± 2.3 h, 95 % CI — guarantee, not guess."
🧪 Self-evaluates for hallucinations. Ragas generates a 30-question grounded eval set from the historian; DeepEval's FaithfulnessMetric and HallucinationMetric grade Apollo's responses end-to-end. Pass gate: faithfulness ≥ 0.95, hallucination = 0.
🪶 Ships an open model that beats frontier. Apollo's runtime LM is Gemma 4 31B Dense; its system prompt is compiled by GEPA (ICLR 2026 Oral) with Claude Opus 4.7 as the reflection LM. The closing demo slide compares vanilla Opus vs vanilla Gemma vs Gemma+GEPA on the same eval, on the same 30 questions.
Apollo is organized as three Domain-Driven bounded contexts, one per developer, with a deliberately tiny shared kernel and explicit anti-corruption layers between them (see ADR-021):
| Context | Path | Owns | Ubiquitous language |
|---|---|---|---|
| 🛠️ Engine | src/engine/ |
Component physics, PINN, coupling matrix, failure models | Component, Cascade, Health, Driver, Forecast |
| 🧮 Simulation & History | src/sim/ |
Run loop, scenarios, policies, GA, historian, retrieval, counterfactual | Run, Scenario, Policy, Tick, Obituary, Dark Twin |
| 💬 Agent & Presentation | src/apollo/ + frontend/ |
Tool calls, citations, refusal, persona, SSE streaming, React UI | Tool Call, Citation, Refusal, Severity, Trace |
Imports flow one way only: Agent → Sim → Engine. The canonical 6-component enum lives in exactly one place (src/engine/contracts.py); a CI architecture test fails the build if string component names appear anywhere outside the enum.
┌─────────────────────────────────────────────────────────┐
│ Agent (Pattern C, 5 tools) │
│ ┌─────────────────────────────────────────────────┐ │
│ │ Pydantic citation validator (Anti-Corruption) │ │
│ └─────────────────────────────────────────────────┘ │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ Simulation: GA · Historian · PyLate · Counterfactual │
└────────────────────────────┬────────────────────────────┘
│
┌────────────────────────────▼────────────────────────────┐
│ Engine: 6 components · Coupling M · 3 cascades · PINN │
└─────────────────────────────────────────────────────────┘
ADR-002 fixes the count at exactly six (2 per subsystem); ADR-006 maps each to the failure model that actually fits its mechanism:
| Subsystem | Component | Failure family | Why this family |
|---|---|---|---|
| 🪣 Recoating | Recoater Blade | Exponential (Archard) + impact Weibull | Continuous height loss + stochastic impact events |
| 🪣 Recoating | Drive Motor | Weibull (β=1.5, η=2000h) | Bearing fatigue, ISO 281 L10 |
| 💧 Printhead | Nozzle Plate | Weibull (β=2.5) | Stochastic clog time-to-event |
| 💧 Printhead | Firing Resistors | Coffin-Manson (c=2.0) | Low-cycle thermal fatigue, IPC-9701A |
| 🔥 Thermal | Heating Element | Coffin-Manson + PINN | Thermal fatigue + 1-D heat diffusion PDE |
| 🔥 Thermal | Insulation Panel | Exponential k_eff decay |
Refractory ceramic-fiber aging |
Five components are pure NumPy and deterministic; the heater is the one PINN, so failure of the learned component cannot cascade across the simulator.
| ID | Name | Path | Modeling |
|---|---|---|---|
| CSC-A | Recoating loop (intra-subsystem) | Blade wear → bed unevenness → motor torque → bearing fatigue | Matrix M |
| CSC-B | Thermal/Printhead loop (showpiece) | Insulation → heater duty → enclosure temp → binder viscosity → nozzle clog → resistor stress | Matrix M + explicit Arrhenius binder viscosity (Ea/R = 4500 K) + Coffin-Manson cycles |
| CSC-C | Powder contamination loop | Blade ceramic flaking → powder contamination → nozzle clog | Matrix M |
CSC-B is the cascade Apollo narrates in depth; it exists because real binder viscosity vs. temperature is Arrhenius, not linear — the matrix alone would be too clean for the showpiece.
user question
│
▼
┌───────────────┐ ┌──────────────────────┐
│ Gemma 4 31B │───▶│ query_historian │ SQLite point query
│ + GEPA │ │ late_interaction_… │ PyLate MaxSim retrieval
│ prompt │───▶│ compare_runs │ cross-policy diff
│ │ │ run_counterfactual │ deepcopy + branch + diff
│ (Claude Agent │───▶│ plot_component_… │ chart payload → React
│ SDK loop) │ └──────────────────────┘
└───────┬───────┘
│ every Citation must resolve to a real (run_id, t, component_id)
▼ row in the historian, or the response becomes a REFUSAL
┌───────────────────────────────────────────────────────┐
│ ApolloResponse {severity, text, citations, tool_calls}│
└────────────┬──────────────────────────────────────────┘
│
▼ SSE: text-delta · tool-call-start · tool-result · citation · done
React chat panel + Recharts dashboard + Langfuse trace link
- Tool count is capped at 5, max tool calls per turn at 3 — adding a sixth tool requires re-running the eval gate.
- Three enforcement layers protect grounding: Pydantic schema → citation resolution against historian → structured refusal template. Fabricated citations are structurally impossible; the dangerous "well-formed response with bogus
(run_id, component, t)" failure mode is caught before the SSEdoneevent fires. - A refusal is a product feature, not a fallback — judges watching the live "Ask Apollo" segment see the guardrail fire in real time.
| Layer | Choice | Why (in one line) |
|---|---|---|
| Physics — 5 components | NumPy + literature-cited Weibull / Coffin-Manson | Deterministic, fast, defensible (ADR-001, ADR-006) |
| Physics — heater | DeepXDE PINN (PyTorch MPS train, CPU infer) | The PDE residual lives in the loss (ADR-005) |
| Coupling | Single 6×6 NumPy matrix M |
One formula, one slide (ADR-004) |
| Persistence | SQLite (historian.db, WAL mode) |
Inspectable with sqlite3 on any laptop (ADR-007) |
| Maintenance optimizer | DEAP Genetic Algorithm (island model) | Visible fitness curve > black-box RL (ADR-011) |
| Counterfactual | Simulator deepcopy + branch + diff | We own the simulator → exact, not estimated (ADR-012) |
| Forecast intervals | MAPIE EnbPi block-bootstrap | Distribution-free 95% CI, wraps any predictor (ADR-015) |
| Retrieval | LightOn LateOn-Code-edge (17M, dim 48) via PyLate | Token-level MaxSim for code-like telemetry (ADR-010) |
| Agent loop | Claude Agent SDK + Pydantic-typed tools | Anthropic-blessed, OTel-native (ADR-008 framework) |
| Runtime LM | Gemma 4 31B Dense + GEPA-compiled prompt | MLH track + ICLR 2026 Oral algorithm (ADR-022) |
| Reflection LM (offline GEPA) | Claude Opus 4.7 via claude CLI |
Smarter-than-student reflection, no API key needed |
| Observability | Langfuse via LangSmith OTel exporter | One env var for full trace timelines (ADR-016) |
| Streaming | sse-starlette + native EventSource |
Typed SSE, zero client deps (ADR-017) |
| Eval | Ragas (testset) + DeepEval (faithfulness / hallucination) | CI-grade pass gate on grounding (ADR-018) |
| Frontend | React + Recharts + Vite | Sufficient at our data scale (ADR-020 §9) |
| Persona | First-person, calm, never alarmist | Brief calls for a "living entity" (ADR-019) |
# 1. install (Python + frontend)
make install
# 2. run the integrated stack (real backend + frontend, with the ASCII art logo)
make dev
# >> backend :: http://localhost:8000 (uvicorn)
# >> frontend :: http://localhost:5173 (vite)
# 2b. or run with mocks only (zero external deps, no API keys needed)
make demo-mock
# 3. backend-only / frontend-only
make backend
make frontend# §6.2 — pre-demo offline driver cache
make cache-drivers
# §9 — tune the AI policy with the GA, emit ga_fitness.csv + policies.yaml
make train-ga
# FR-2.4 / §8.3 — materialize all 9 (scenario × policy) runs into historian.db
make build-grid
# §12.1 — build the late-interaction PyLate index over the historian
make build-index
# Plan B demo gate — the whole thing in one shot
make plan_b_demomake test # engine only, fast
make test-plan-b # full Plan B suite + 85% coverage gate
make test-plan-c # Plan C definition-of-done sweep (agent, sse, eval, architecture)
make test-gepa # verifies the GEPA-compiled prompt artifact + comparison gateThe "why" of every load-bearing choice lives in docs/adr/. Each ADR documents the context, the decision, the alternatives and why each was rejected, and the consequences (positive, negative, neutral).
| # | Decision | Status |
|---|---|---|
| 001 | Hybrid rule-based + PINN modeling | Accepted |
| 002 | Six components across three subsystems | Accepted |
| 003 | Three parallel cascades, not one chain | Accepted |
| 004 | Linear 6×6 coupling matrix M |
Accepted |
| 005 | DeepXDE for the heating-element PINN | Accepted |
| 006 | Three failure-model families | Accepted |
| 007 | SQLite as the historian | Accepted |
| 008 | Claude Agent SDK + Sonnet-class | Partially superseded by ADR-022 (model only) |
| 009 | Pattern C — Agentic Diagnosis | Accepted |
| 010 | Late-interaction retrieval (LateOn-Code-edge + PyLate) | Accepted |
| 011 | Genetic Algorithm (DEAP) for maintenance | Accepted |
| 012 | Simulator-checkpoint counterfactual | Accepted |
| 013 | 3 × 3 benchmark + Dark Twin framing | Accepted |
| 014 | Pydantic-enforced citations + refusal templates | Accepted |
| 015 | MAPIE conformal prediction intervals | Accepted |
| 016 | Langfuse for agent observability | Accepted |
| 017 | Server-Sent Events for streaming | Accepted |
| 018 | Ragas + DeepEval grounding eval | Accepted |
| 019 | Apollo first-person persona | Accepted |
| 020 | Out-of-scope decisions (17 items) | Accepted |
| 021 | DDD with three bounded contexts | Accepted |
| 022 | Gemma 4 31B + GEPA-compiled prompt | Accepted (supersedes ADR-008's model only) |
ADR-020 consolidates 17 capabilities considered and skipped, with the one-sentence answer for each:
🔇 No voice UI — pretty wrapper, hollow if the backend looks shallow.
🚫 No reinforcement learning — sim-to-real generalization is openly unsolved; GA gives a visible fitness curve, RL gives a coin flip.
🚫 No custom Metal/CoreML kernels — at ~10–50k PINN params, MPS launch overhead is worse than CPU.
🚫 No NVIDIA Omniverse / photoreal twin — the brief is about decision intelligence, not graphics.
🚫 No FDM / NASA C-MAPSS training data — domain mismatch will be called out in 30 seconds.
🚫 No time-series foundation models — sledgehammer for 6 simulated components, contradicts the PINN narrative.
🚫 No survival models, no PyOD anomaly detection — duplicative second source of truth that can disagree with ground truth on stage.
🚫 No causal-DAG library (DoWhy / EconML / CausalPy) — we own the simulator, the counterfactual is exact.
🚫 No local LLM fallback — would silently degrade grounding below the NFR-6 gate.
🚫 No Vercel AI SDK / Next.js rewrite — sse-starlette + native EventSource is 30 lines.
🚫 No MCP-style tool servers — five callables sharing a process don't need IPC.
🚫 No multi-printer fleet view, no Twilio phone calls, no operator-persona switching — pure scope creep against a 36-hour clock.
Each rejection has a "reconsider if…" clause documenting the post-hackathon road.
- 0% hallucination + ≥ 0.95 faithfulness on the FR-W.9 grounding eval (
deepeval test run, exit code 0). - 100% citation coverage on every non-refusal response (Pydantic invariant on
ApolloResponse). - ≥ +25% uptime for AI policy vs FIXED schedule across the 3-scenario grid (target +34%).
- ≥ 90% empirical coverage at 95% nominal CI for MAPIE forecast bands on the held-out
Stressedscenario. - PINN inference < 5 ms CPU per call (NFR-3), enforced in CI.
- Engine step < 50 ms for all 6 components combined (NFR-2).
- Agent end-to-end < 6 s p95 (NFR-5).
- GEPA-compiled Gemma ≥ vanilla Opus on the same 30-question eval — measured, rendered on the closing slide.
The full ADR-022 pipeline is wired end-to-end — DSPy GEPA with Gemma 4 31B as the student LM, Claude Opus 4.7 (via the claude CLI) as the reflection LM, and a tool-use eval that scores Apollo's five tools on tool choice, schema-valid args, execution, refusal correctness, citation behavior, and grounded answer quality. The compile path refuses fake/simulated GEPA unless explicitly allowed; the compiled artifact lives at config/agent.system_prompt.gepa.txt. Runtime hardening (dark-twin aliases, Apollo/fixed/dark-twin policy comparison, run-level plotting, refusal fallbacks) was added where the eval surfaced Gemma weaknesses.
The saved comparison currently reflects a 10-item smoke run, not the expanded final benchmark. On that run, GEPA-Gemma and vanilla Gemma tied on overall pass rate, but GEPA modestly improved the grounding signals that matter most:
| Metric | Vanilla Gemma | GEPA Gemma | Δ |
|---|---|---|---|
| Pass rate | 0.70 | 0.70 | ±0 |
| Faithfulness | 0.670 | 0.688 | +0.018 |
| Missing required citations | 2 | 1 | −1 |
| Citation resolve rate | 0.125 | 0.333 | +0.208 |
| Avg latency | 30.3 s | 23.6 s | −6.7 s |
What this supports. A real, non-simulated GEPA compile produced a Gemma prompt with measurably better citation grounding and lower latency than vanilla Gemma — early evidence that the optimizer is doing the work the ADR claims.
What it does not yet support. The "GEPA-Gemma ≥ vanilla Opus" demo-gate target is not proven on this 10-item run. The expanded, parallelized benchmark is staged but unfinished; until it completes, the defensible claim is "early evidence of improved grounding," not "closes the gap to frontier."
- We do not claim our parameters match a real HP Metal Jet S100. Each value falls inside a published range for the analogous mechanism in the analogous component class; specific point estimates are synthetic and disclosed as such (ADR-006 §"Disclosed assumptions").
- "Dark Twin" is marketing copy — UI and demo narration only; the technical report uses "NONE-policy baseline" (ADR-013).
- The PINN's training data is synthetic, generated from the same physics it learns — we frame this as a consistency check, not a generalization claim (ADR-005).
- The agent's prompt was compiled, not hand-written. The exact text lives in
config/agent.system_prompt.gepa.txtand is shown on a demo slide for any judge who wants to read it (ADR-022).
- 📐
docs/PRD.md— full product requirements - 🗺️
docs/plans/— three-developer parallel-build plan - 📜
docs/adr/— every load-bearing decision with alternatives & references - 📊
docs/eval/— grounding eval results + GEPA compile log - 🎤
docs/PITCH_kametrina.md— the demo narrative - 🛠️
Makefile— every reproducible step
Apollo is a hackathon submission for HP's "When AI meets reality" challenge and Major League Hacking's "Best Use of Gemma" track at HackUPC 2026 in Barcelona. Built in 36 hours under deliberate scope discipline; defended by 22 ADRs.